快来学习!全网最全的Ambari知识库闪亮登场
大家好,我是create17。自从2017年实习,我就开始围绕Ambari做相关工作。期间做过Ambari安装部署、页面生产级别的汉化、Ambari自定义服务集成、前端页面开发、后端API接口开发、Ambari Server HA、部分原生bug修改,以及HDP相关常用组件的基本使用。
关于HDP,除了常用组件的使用测试写文档,还花费了大量时间研究Kerberos,少量时间研究Knox。
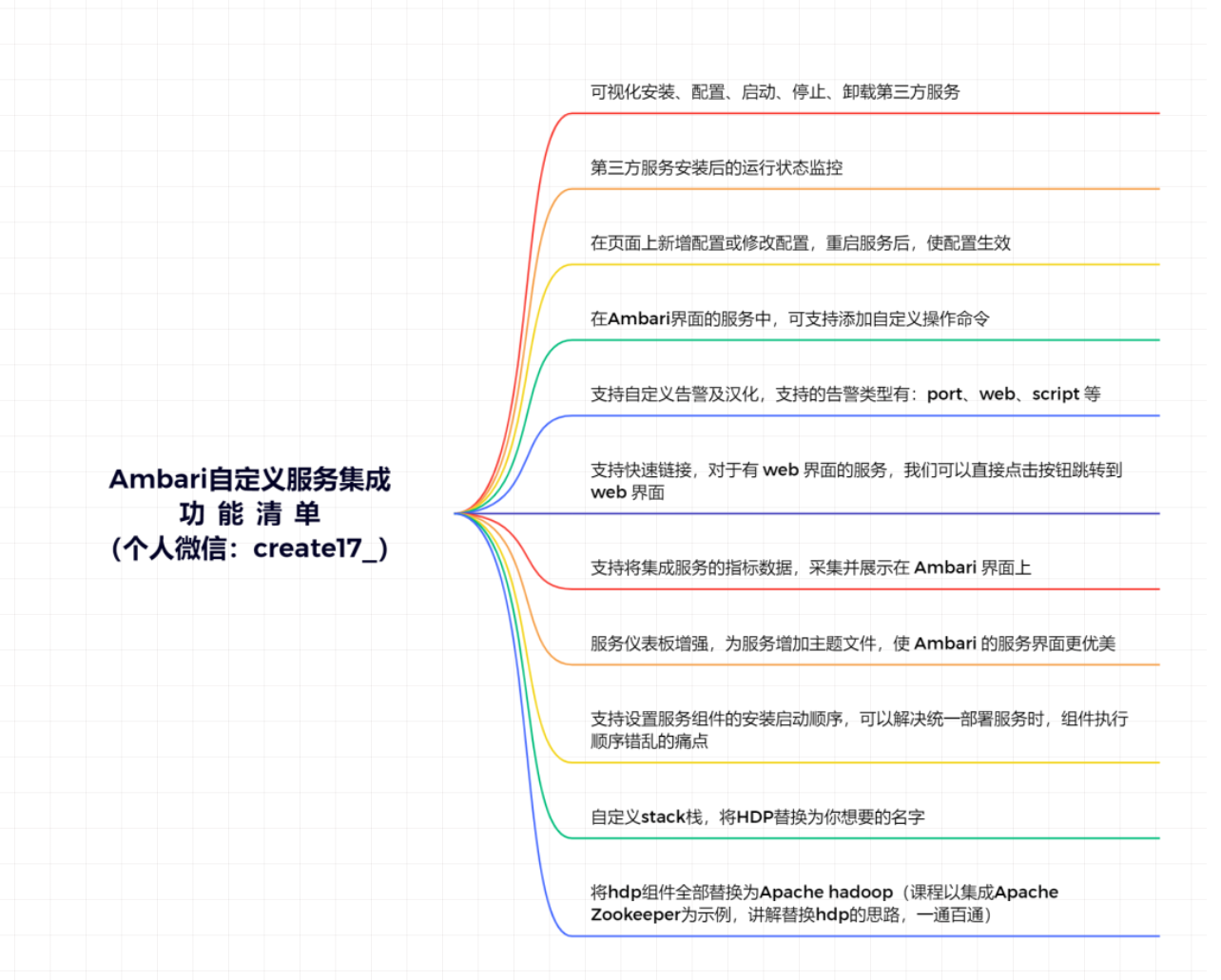
Ambari自定义服务集成,在Ambari 2.6.x 和 2.7.x 版本也集成过很多组件,比如:Elasticsearch、HUE、Kylin、PostgreSQL + PostGIS、Kerberos KDC Server、JanusGraph等。如此多集成服务的经验,使我对Ambari自定义服务集成有了很深的理解,简直就是万物皆可集成。于是花费很多的精力去投入,输出了《Ambari自定义服务集成十八讲》课程,内容干货同时享有的权益有很多,具体可通过《让 Ambari 不再难学,让大家都能熟练集成自定义服务》了解详情。截止2022.11月,已累计210+学员报名。