转 | 如何防止elasticsearch的脑裂问题
本文转载自 祝坤荣 的博客,
地址为:https://segmentfault.com/a/1190000004504225#articleHeader3
我们都遇到过这个 - 在我们开始准备一个 elasticsearch 集群的时候,第一个问题就是“集群需要有多少节点?”。我想大家都知道,这个问题的答案取决于很多因素,例如期望的负载,数据大小,硬件等。这篇博文不会深入解释如何调整集群大小的细节,而是去关注另一个同样重要的事情 - 如何避免脑裂问题。
一、什么是脑裂?
让我们看一个有两个节点的 elasticsearch 集群的简单情况。集群维护一个单个索引并有一个分片和一个复制节点。节点1在启动时被选举为主节点并保存主分片(在下面的 schema 里标记为 0P ),而节点2保存复制分片(0R)。

现在,如果在两个节点之间的通讯中断了,会发生什么?由于网络问题或只是因为其中一个节点无响应(例如 stop-the-world垃圾回收),这是有可能发生的。
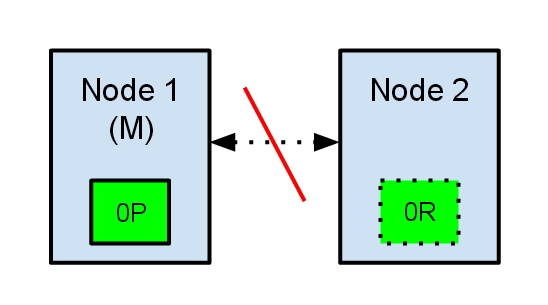
两个节点都相信对方已经挂了。节点1不需要做什么,因为它本来就被选举为主节点。但是节点2会自动选举它自己为主节点,因为它相信集群的一部分没有主节点了。在 elasticsearch 集群,是有主节点来决定将分片平均的分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升复制节点为主节点。
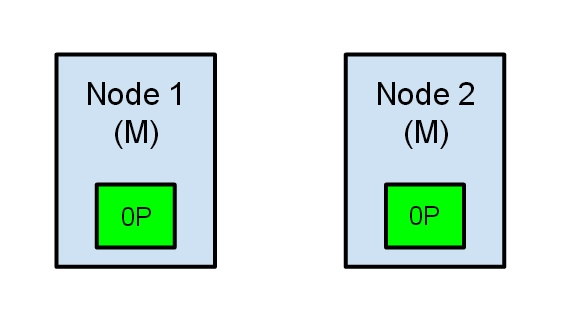
现在我们的集群在一个不一致的状态了。打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。在这种情况下,分片的两份数据分开了,如果不做一个全量的重索引很难对它们进行重排序。在更坏的情况下,一个对集群无感知的索引客户端(例如,使用REST接口的),这个问题非常透明难以发现,无论哪个节点被命中索引请求仍然在每次都会成功完成。问题只有在搜索数据时才会被隐约发现:取决于搜索请求命中了哪个节点,结果都会不同。
二、如何避免脑裂问题?
elasticsearch 的默认配置很好。但是 elasticsearch 项目组不可能知道你的特定场景里的所有细节。这就是为什么某些配置参数需要改成适合你的需求的原因。这篇博文里所有提到的参数都可以在你 elasticsearch 安装地址的 config 目录中的 elasticsearch.yml 中更改。
要预防脑裂问题,我们需要看的一个参数就是 discovery.zen.minimum_master_nodes。这个参数决定了在选主过程中需要 有多少个节点通信。缺省配置是1.一个基本的原则是这里需要设置成 N/2+1, N是集群中主资格节点的数量。 例如在一个三主资格节点的集群中, minimum_master_nodes 应该被设为 3/2 + 1 = 2(四舍五入)。
让我们想象下之前的情况下如果我们把 discovery.zen.minimum_master_nodes 设置成 2(2/2 + 1)。当两个节点的通信失败了,节点 1 会失去它的主状态,同时节点 2 也不会被选举为主。没有一个节点会接受索引或搜索的请求,让所有的客户端马上发现这个问题。而且没有一个分片会处于不一致的状态。
我们可以调的另一个参数是 discovery.zen.ping.timeout。它的默认值是 3 秒并且它用来决定一个节点在假设集群中的另一个节点响应失败的情况时等待多久。在一个慢速网络中将这个值调的大一点是个不错的主意。这个参数不止适用于高网络延迟,还能在一个节点超载响应很慢时起作用。
三、两节点集群?
如果你觉得(或直觉上)在一个两节点的集群中把 minimum_master_nodes 参数设成2是错的,那就对了。在这种情况下如果一个节点挂了,那整个集群就都挂了。尽管这杜绝了脑裂的可能性,但这使elasticsearch另一个好特性 - 用复制分片来构建高可用性 失效了。
如果你刚开始使用 elasticsearch ,建议配置一个3节点集群。这样你可以设置 minimum_master_nodes 为 2 ,减少了脑裂的可能性,但仍然保持了高可用的优点:你可以承受一个节点失效但集群还是正常运行的。
但如果已经运行了一个两节点 elasticsearch 集群怎么办?可以选择为了保持高可用而忍受脑裂的可能性,或者选择为了防止脑裂而选择高可用性。为了避免这种妥协,最好的选择是给集群添加一个节点。这听起来很极端,但并不是。对于每一个 elasticsearch 节点你可以设置 node.data 参数来选择这个节点是否需要保存数据。缺省值是“true”,意思是默认每个 elasticsearch 节点同时也会作为一个数据节点。
在一个两节点集群,你可以添加一个新节点并把 node.data 参数设置为“false”。这样这个节点不会保存任何分片,但它仍然可以被选为主(默认行为)。因为这个节点是一个无数据节点,所以它可以放在一台便宜服务器上。现在你就有了一个三节点的集群,可以安全的把 minimum_master_nodes 设置为2,避免脑裂而且仍然可以丢失一个节点并且不会丢失数据。
四、结论
脑裂问题很难被彻底解决。在 elasticsearch 的 问题列表 里仍然有关于这个的问题, 描述了在一个极端情况下正确设置了 minimum_master_nodes 的参数时仍然产生了脑裂问题。 elasticsearch 项目组正在致力于开发一个选主算法的更好的实现,但如果你已经在运行 elasticsearch 集群了那么你需要知道这个潜在的问题。
如何尽快发现这个很重要。一个比较简单的检测问题的方式是,做一个对/_nodes下每个节点终端响应的定期检查。这个终端返回一个所有集群节点状态的短报告。如果有两个节点报告了不同的集群列表,那么这是一个产生脑裂状况的明显标志。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

