Elasticsearch入门
一、基本概念
1. 节点(Node)和集群(Cluster)
集群是一个或多个节点(服务器)的集合, 这些节点共同保存整个数据,并在所有节点上提供联合索引和搜索功能。一个集群由一个唯一集群ID确定,并指定一个集群名(默认为“elasticsearch”)。该集群名非常重要,因为节点可以通过这个集群名加入集群,一个节点只能是集群的一部分。
2. Index(索引)
索引(index)类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。索引名称必须是全部小写,不能以下划线开头,不能包含逗号。
下面的命令可以查看当前节点的所有 Index。
1 | curl -X GET 'http://localhost:9200/_cat/indices?v' |
3. Type(类型)
在索引中,我们可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全由开发者决定。通常,为具有一组公共字段的文档定义类型。
例如,假设开发者运行博客平台并将所有数据存储在一个索引中。在此索引中,我们可以为用户数据定义类型,为博客数据定义另一种类型,并为注释数据定义另一种类型。我们可以把索引理解成数据库文档中的表。
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
下面的命令可以列出每个 Index 所包含的 Type。
1 | curl 'localhost:9200/_mapping?pretty=true' |
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
4. Document(文档)
文档是可索引信息的基本单元,以JSON表示。你可以用其来定义单个产品信息或是员工信息。我们可以把文档理解为数据库文档中的行列数据。在索引/类型中,您可以存储任意数量的文档。文档有几个共同不可缺的属性,分别为 _index, _type, _id, 针对特定一个或一类文档进行操作时,必须指定这些属性。
需要注意的是:虽然文档物理上是驻留在索引中,但实际上文档必须索引/分配给索引中的类型。
Document 使用 JSON 格式表示,下面是一个例子。
1 | { |
5. Mapping(映射)
模式映射(schema mapping,或简称映射)用于定义索引结构。Elasticsearch在映射中存储有关字段的信息。每一个文档类型都有自己的映射,即使我们没有明确定义。映射在文件中以JSON对象传送。
6. Field(字段)
ElasticSearch里的最小单元 相当于数据的某一列,类似于json里一个键。
7. 相关概念在关系型数据库和ElasticSearch中的对应关系
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库Database | 索引Index,支持全文检索 |
| 表Table | 类型Type |
| 数据行Row | 文档Document,但不需要固定结构,不同文档可以具有不同字段集合 |
| 数据列Column | 字段Field |
| 模式Schema | 映射Mapping |
8. Shards(分片)
当有大量的文档时,由于内存的限制、硬盘能力、处理能力不足、无法足够快地响应客户端请求等,一个节点可能不够。在这种情况下,数据可以分为较小的称为分片(shard)的部分(其中每个分片都是一个独立的Apache Lucene索引)。每个分片可以放在不同的服务器上,因此,数据可以在集群的节点中传播。
当你查询的索引分布在多个分片上时,Elasticsearch会把查询发送给每个相关的分片,并将结果合并在一起。此外,多个分片可以加快索引。
9. Replica(副本)
为了提高查询吞吐量或实现高可用性,可以使用分片副本。副本(replica)只是一个分片的精确复制,每个分片可以有零个或多个副本。换句话说,Elasticsearch可以有许多相同的分片,其中之一被自动选择去更改索引操作。这种特殊的分片称为主分片(primary shard),其余称为副本分片(replica shard)。在主分片丢失时,例如该分片数据所在服务器不可用,集群将副本提升为新的主分片。
二、新建、删除索引
索引名称必须为小写
1 | curl -X PUT 'localhost:9200/weather' |
服务器返回一个 JSON 对象,里面的acknowledged字段表示操作成功。
1 | { |
然后,我们发出 DELETE 请求,删除这个 Index。
1 | curl -X DELETE 'localhost:9200/weather' |
服务器也会返回一个JSON对象,里面的acknowledged字段表示操作成功。
1 | { |
三、插入数据
POST新增索引,数据
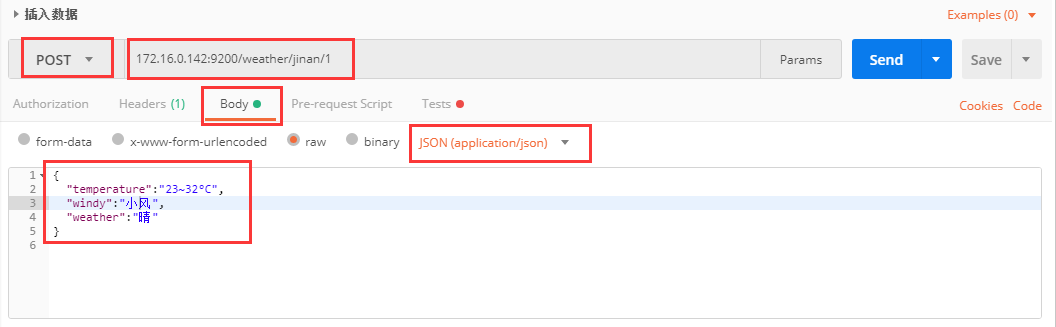
服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
1 | # result 的值为 created |
四、更新数据
PUT更新索引,数据,get获取,分词等
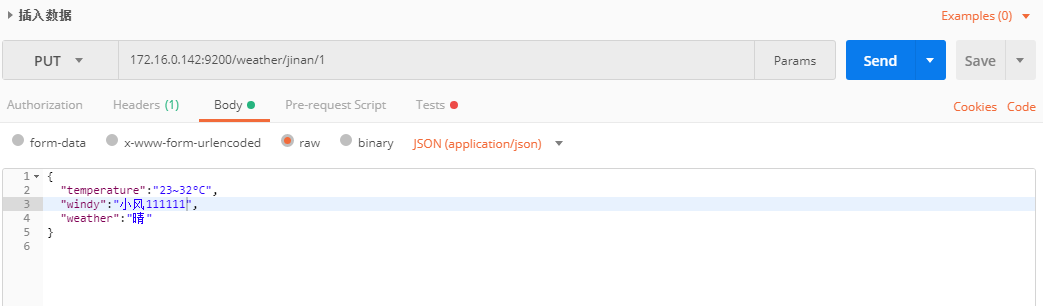
1 | # _version的值为 2 ,result的值为 updated |
五、数据查询
使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录。
1 | # curl -X GET '172.16.0.142:9200/weather/jinan/_search' |
上面代码中,返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
1 | total : 返回记录数,本例是5条。 |
返回的记录中,每条记录都有一个_score字段,表示匹配的程序,默认是按照这个字段降序排列。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2018/07/29/ELK/Elasticsearch/基础知识/ElasticSearch入门.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

