Java api 远程访问 hdfs ha 通用写法总结
一、前言
今天将自己的程序部署到生产环境中,发现执行 hdfs 相关操作时报错了。原来是测试环境是 nameNode 单节点,生产环境上是 nameNode HA 。
自己写的 hdfs 连接不适配 nameNode HA 。就很烦躁,还得增加工作量来改代码。
以前的代码如下图所示:
1 | <dependency> |
1 | private static Configuration conf = new Configuration(); |
就这么简单,但如果环境是 nameNode HA 状况的话,当 nameNode 切换后,这种实现方式就可能会报错,那还得改代码。
二、适配 nameNode HA 的写法
基于以上代码,我又适配了 nameNode HA 状态的写法:
1 | private static Configuration conf = new Configuration(); |
这样实现起来倒也不难,但也仅仅是适配于 nameNode HA 状态的写法。我们先来分析一下为什么要加这些配置。
- fs.defaultFS:客户端连接 HDFS 时,默认的路径前缀。如果配置了 nameNode HA 的话,这里的值就为:hdfs://[nameservice id] 。
- dfs.nameservices 命名空间的逻辑名称。
- dfs.ha.namenodes.[nameservice id] 命名空间中所有 nameNode 的唯一标示名称。可以配置多个,使用逗号分隔。该名称可以让 dataNode 知道每个集群的所有 nameNode 。
- dfs.namenode.rpc-address.[nameservice id].[namenode name]:HDFS Client访问HDFS,就是通过 RPC 实现的,代表每个 nameNode 监听的 RPC 地址。
dfs.client.failover.proxy.provider.[nameservice id]:配置 HDFS 客户端连接到 Active NameNode 的一个 java 类。
这种方式如果用于 单nameNode 环境的话,也不行,也不适配。
三、通过加载 hdfs 配置文件,适配单/双 nameNode 环境
那如何让它一步到位呢?
让项目直接加载 hdfs 相关配置文件就好啦。由于上面涉及到的配置在 hdfs-site.xml 和 core-site.xml 文件中,所以要加载这两个文件,把这俩文件放在 resource 目录下即可,然后代码如下:
1 | private static Configuration conf = new Configuration(); |
hdfs-site.xml 和 core-site.xml 文件可以通过 cdh-manager 页面来下载获取:
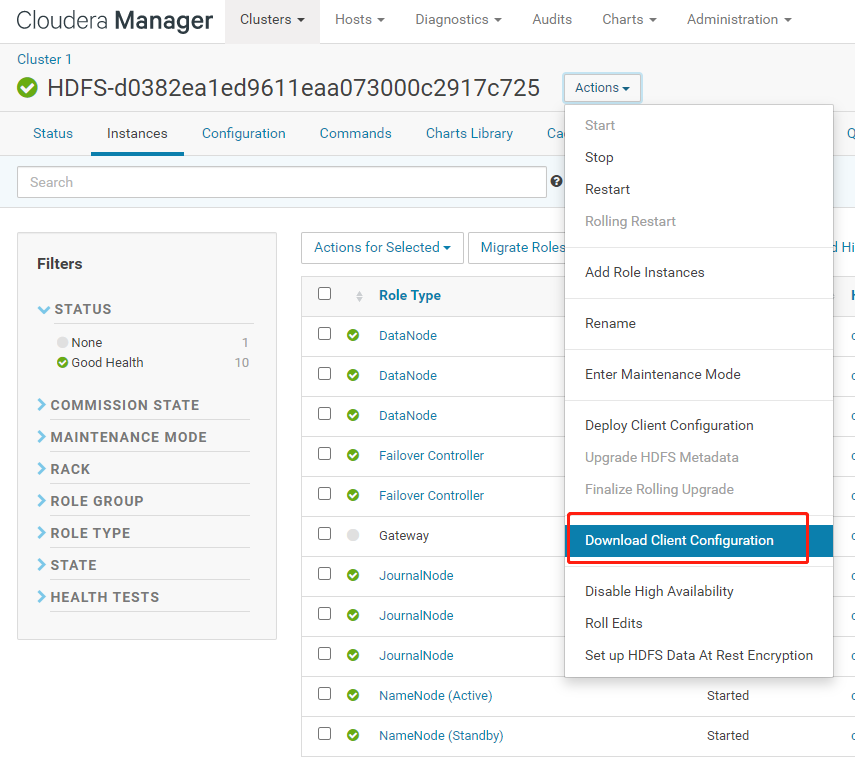
强烈建议用加载 hdfs 配置文件的方式,来实现对 HDFS 客户端的操作。如果还有用前一种 conf.set() 写法来获取 hdfs 客户端的话,建议赶紧改成 加载 hdfs 配置文件的方式,好用方便,适配性强 。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2020/12/05/HDFS/hdfs-ha-java-api.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

