Elasticsearch集群状态恢复(红色 -> 绿色)
参考:https://zhuanlan.zhihu.com/p/101608973
- _cluster/health?pretty
- _cluster/health?pretty&level=indices
- _cluster/health?pretty&level=shards
1、集群状态说明
Elasticsearch 集群状态说明:
- GREEN:集群中所有分片均已分配
- YELLOW:集群中所有主分片均已分配,但未分配一个或多个副本分片。如果集群中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。
- RED:至少有一个或多个主分片未分配,所以导致某些数据不可用。
2、集群环境说明
出问题的 Elasticsearch 集群共有两个节点,==目前两节点 es 服务运行正常,内存、磁盘空间都足够。==集群状态为 red ,有主分片丢失。所有的索引都是 1 个副本,所以正常情况下,该集群的状态为 green 才对。
在这里,推荐一个运维工具:cerebro ,可视化操作 ES ,感觉比 head 插件要好。在 cerebro 页面上,我们可以清楚地看到都有哪些未分配的分片。
3、集群恢复
3.1、red -> yellow
可以先执行 curl -XGET http://es_ip:9200/_cluster/allocation/explain ,查看集群分片分配失败的原因。
然后可以执行 curl -XPOST "http://es_ip:9200/_cluster/reroute?retry_failed=true" 命令来分配未被分配的分片。返回结果中,有针对每个索引的每个分片的状态说明。
执行完上述命令后,我们可以执行 curl -XGET http://es_ip:9200/_recovery?active_only=true 来查看集群是否恢复以及恢复进度。当参数 active_only 为 true 时,表示返回结果只显示正在恢复的索引列表信息。
我多执行了几遍 curl -XPOST "http://es_ip:9200/_cluster/reroute?retry_failed=true" 分片分配命令,把所有的主分片都分配完成了,集群也就变成了 yellow 状态。==在这里,我的集群是这样子恢复到 yellow 状态的。==
3.2、yellow -> green
又执行了一遍 curl -XGET http://es_ip:9200/_cluster/allocation/explain 命令,发现未分配的分片都报:

根据命令返回的信息分析,副本分片未分配的原因是:ALLOCATION_FAILED,已经超过了最大重试次数 5 次,当前分片分配状态是 “no attempt”,时间是5月底,不是当前时间。所以,首要解决的就是把这个重试次数清零,让其再重新分配下,可能就好了。可能当时 5 月底的时候,集群有节点一直没启动,浪费了重试次数。
期间,又尝试了几种方法,都还是报 ALLOCATION_FAILED,已经超过了最大重试次数 5 次,当前分片分配状态是 “no attempt”,时间是5月底,不是当前时间。
直到我做了以下操作:
1)首先禁用自动分配
1 | curl -XPUT http://es_ip:9200/_cluster/settings -d '{ |
2)然后滚动重启 es 集群
3)集群启动后再改回配置
1 | curl -XPUT http://localhost:9200/_cluster/settings -d '{ |
persistent 是 就永久配置 的意思,可以将值设为 null 来达到删除该配置的目的。
4)重新执行分配命令
又执行了 curl -XPOST "http://es_ip:9200/_cluster/reroute?retry_failed=true" 命令。然后,这时候就惊喜的发现,未分配分片的状态改变了,由 ALLOCATION FAILED 都变成了 CLUSTER_RECOVERED 。
执行了 curl -XGET http://es_ip:9200/_cluster/allocation/explain ,发现集群分片果然在恢复了。
5)又出现问题
过了一会,发现集群分片恢复完了,还是有一些分片没有分配,这是怎么回事呢?
于是又执行了:curl -XGET http://es_ip:9200/_cluster/allocation/explain,发现提示:
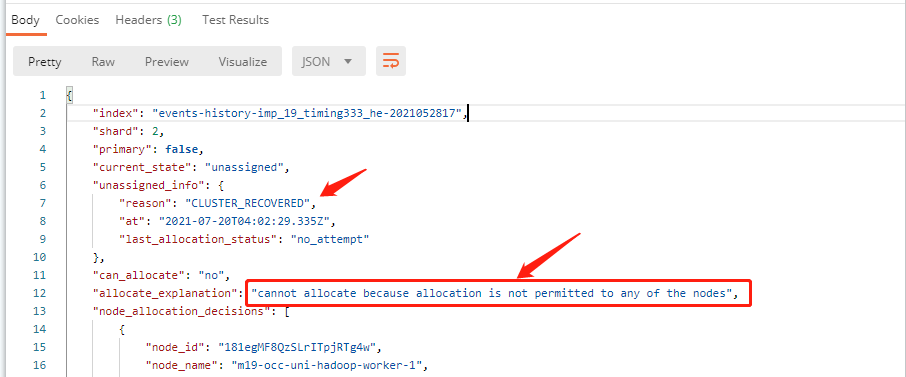
然后从 cerebro 上发现,某个节点磁盘不够了。然后又清理了一部分磁盘垃圾数据,重新执行 curl -XPOST "http://es_ip:9200/_cluster/reroute?retry_failed=true" ,过了一会,就发现集群状态变为 green,所有分片均已被分配。
4、集群分片负载均衡
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2021/07/20/ELK/Elasticsearch/疑难问题/es-status-red-to-green.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

