MapReduce工作原理
前言
这篇文章是我之前在自学 MapReduce 的笔记,想着最近再回顾一下 MapReduce 的原理,于是就整理了一下。
MapReduce 采用的是“分而治之”的数据,当我们处理大规模的数据时,将这些数据拆解成多个部分,并利用集群的多个节点同时进行数据处理,然后将各个节点得到的中间结果进行汇总,经过进一步的计算(该计算也是并行进行的),得到最终结果。
一、Hadoop中的Configuration类剖析
Configuration 是 Hadoop 中五大组件的公用类,org.apache.hadoop.conf.Configuration。这个类是作业的配置信息类,任何作用的配置信息必须通过 Configuration 传递,因为通过 Configuration 可以实现在多个 mapper 和多个 reducer 任务之间共享信息。
1 | Configuration conf = new Configuration(); |
二、MapReduce中IntWritable(1)
IntWritable 是 Hadoop 中实现的用于封装 Java 数据类型的类,它的原型是 public IntWritable(int value) 和 public IntWritable() 两种。所以 new IntWritable(1) 是新建了这个类的一个对象,而数值 1 这是参数。在 Hadoop 中它相当于 java 中 Integer 整形变量,为这个变量赋值为 1 。
在 wordCount 这个程序中,后面有语句 context.writer(word, one),即将分割后的字符串形成键值对,<单词,1>,就是这个意思。
三、wordCount实例讲解
1、Split阶段(分片输入)
如下图所示,有两份文件,经过分片处理之后,会被分成三个分片(split1,split2,split3)。依次作为map阶段的输入。
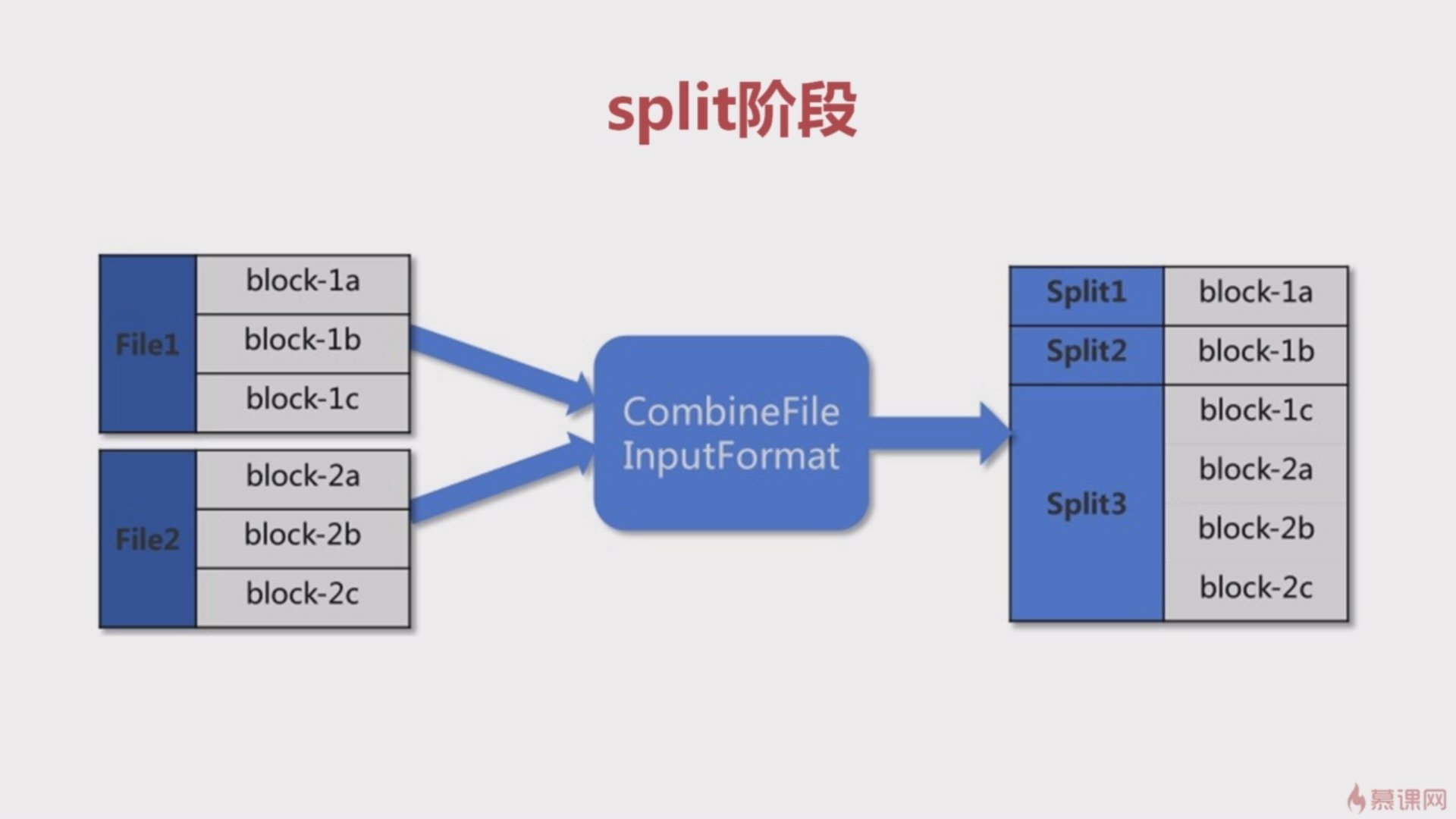
下图有三行文本,经过分片处理之后,产生了三个分片,每个分片就是一行的三个单词,分别作为 map 阶段的输入。

2、Map阶段(需要编码)
Split 阶段的输出作为 Map 阶段的输入,一个分片对应一个 Map 任务。在 Map 阶段中,读取 value 值,将 value 值拆分为 <key,value> 的形式。key 为 每个单词,value 为 1。
Map 阶段需要考虑 key 是什么,value 是什么。特别是 key ,他将作为后面 reduce 的依据。输出结果例如:<Deer, 1>,<River, 1>,<Bear, 1>,<Bear, 1>。
Map 阶段的输出会作为 Shuffle 阶段的输入。
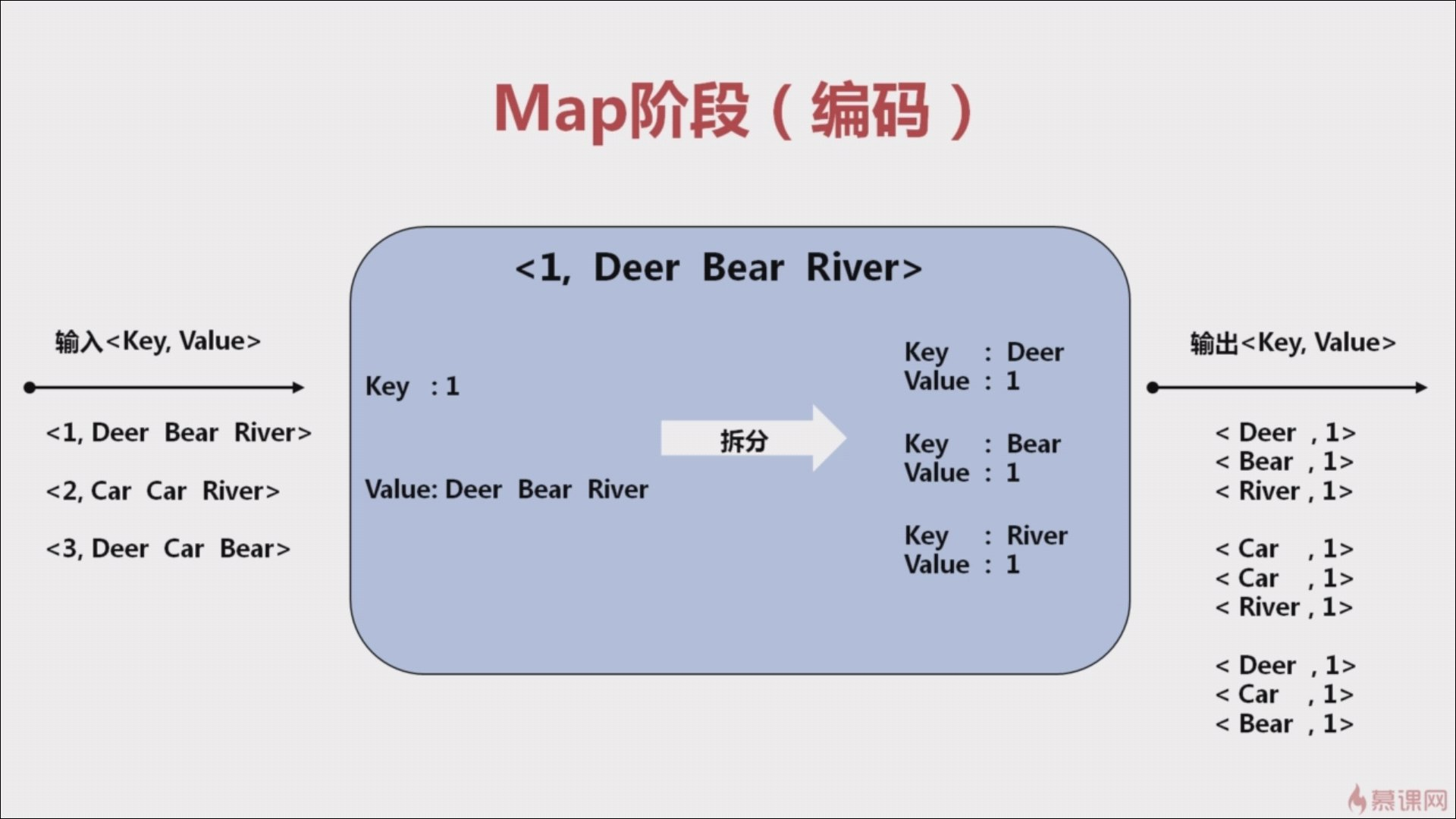
自定义 map 继承 Mapper ,重写 Mapper 中的方法 map(Object key, Text value, Context context) 。key 和 value 表示输入的 key 和 value ,处理后的数据写入 context,使用方法 context.write(key, value) ,这里的 key 和 value 会传递给下一个过程。
Mapper 参数类型有以下几种:
- Mapper<Object, Text, Text, IntWritable>
- Mapper<Text, Text, Text, Text>
- Mapper<Text, IntWritable, Text, IntWritable>
第一、二个表示输入 map 的 key 和 value ,从 InputFormat 传过来的,key 为每行文本首地址相对于整个文本首地址的偏移量,value 默认是一行。
第三、四个表示输出的 key 和 value 。
可优化点:可以自定义一个合并函数,hadoop 在 Map 阶段会调用它对本地数据进行预合并,可以减少后面的数据传输量和计算量。
3、Shuffle阶段(比较复杂)
Shuffer 阶段过程比较复杂,可以理解为从 Map 输出到 Reduce 输入的过程,而且涉及到网络传输。
将 Map 中 key 相同的都归置到一起,作为一个 Reduce 的输入。输出结果例如:<Car,{1,1,1}>

可优化点:虽然 shuffle 阶段有默认规则,但我们也可以通过自定义分区函数来优化我们的算法。
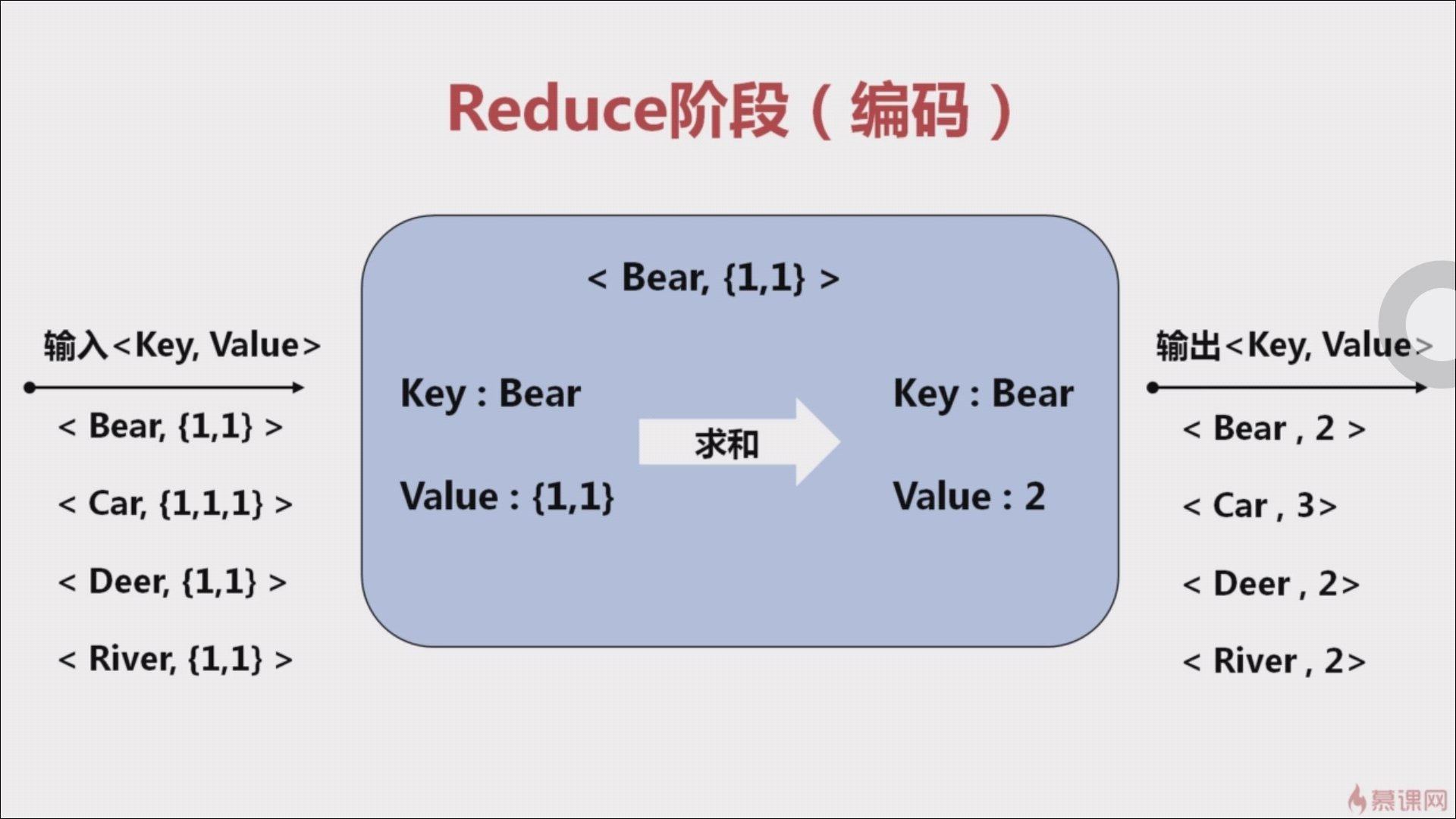
4、Reduce阶段(需要编码)
将 key 相同的数据进行累计。输出结果例如:<Beer, 3>。
四、wordCount代码
这是我之前写的 wordCount 代码,可以通过代码再了解一下 MapReduce 的流程。
- 自定义mapper方法
- 自定义reducer方法
- main方法
- Configuration conf = new Configuration();
- conf.set(“…..”); 以集群的方式进行,跨平台提交,设置自己生成的jar包
- 生成Job作业
- 自定义输入路径
- 自定义mapper和reducer
- 设置key和value的类型
- 自定义输出路径
- 结束:提交这个job给yarn集群。
1 | import org.apache.hadoop.conf.Configuration; |
五、job.setOutputKeyClass和job.setOutputValueClass的注意点
job.setOutputKeyClass 和 job.setOutputValueClass 在默认情况下是同时设置 map 阶段和 reduce 阶段的输出,也就是说只有 map 和 reduce 输出是一样的时候才不会出问题。
当 map 和 reduce 的输出类型不一样时,就需要通过 job.setMapOutputKeyClass 和 job.setMapOutputValueClass 来设置 map 阶段的输出。
六、总结
总的来说,MapReduce 分为四个过程,分别是 Split、Map、Shuffle、Reduce 这四个阶段。
- Split 阶段是将大文件切分为几个小文件,也就是分片。
- Split 阶段的输出作为 Map 阶段的输入,一个分片对应一个 Map 任务。在 Map 阶段中,读取 value 值,将 value 值拆分为 <key,value> 的形式。就 wordCount 而言,key 为 每个单词,value 为 1。
- Shuffer 阶段过程比较复杂,可以理解为从 Map 输出到 Reduce 输入的过程。就 wordCount 而言,是将 Map 中 key 相同的都归置到一起,作为一个 Reduce 的输入。
- Reduce 阶段汇总结果。就 wordCount 而言,将 key 相同的数据进行累计。
如果有人再问你 MapReduce 工作原理的话,可以将上面的话说给他听。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2018/07/15/MapReduce/how-mapreduce-works.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

