Kerberos应用
环境说明
- Ambari 2.6.1.0
- HDP 2.6.4
- Kerberos 1.14.1
前言
前面的文章介绍了《Kerberos原理–经典对话》、《Kerberos基本概念及原理汇总》、《基于ambari的Kerberos安装配置》、《Windows本地安装配置Kerberos客户端》,已经成功安装了Kerberos KDC server,也在Ambari上启用了Kerberos,接下来我们再来研究一下如何使用Kerberos。
一、概要
在Ambari页面启用Kerberos向导成功后,在Kerberos数据库中,就存放着许多Principal,在/etc/security/keytabs目录下也存放着很多keytab。这些principal与keytab是一一对应的,可以理解为锁与钥匙的关系。
关于Kerberos的一些基础概念,可以戳《Kerberos基本概念及原理汇总》了解。
如果使用各服务的话,就需要进行Kerberos认证了。
准确的说,是开启了kerberos认证的组件都必须先kinit后才可以使用,具体权限取决于组件本身的授权机制(ACL/Sentry等)
二、访问Kerberos数据库查看principal
1. 在kerberos KDC所在机器并且当前用户是root上操作
访问Kerberos数据库:
1 | kadmin.local |

查看Kerberos principal:
1 | 第一种方式,在kadmin.local模式,直接输入 |
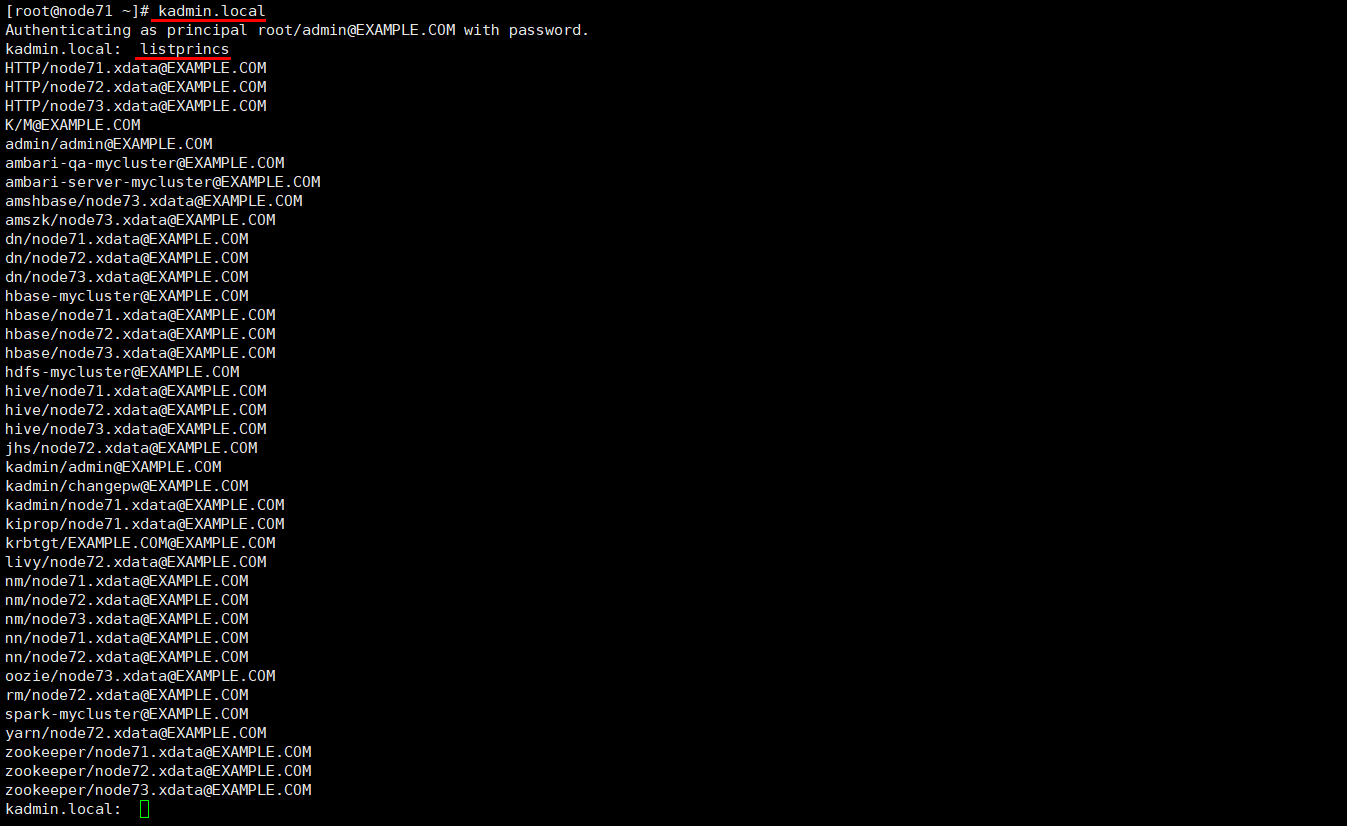
2. 当前用户是非root用户或在其它机器上操作
我们选择一台Kerberos从节点上访问Kerberos数据库,先使用kinit进行身份认证:
1 | kinit admin/admin |

然后再使用kadmin命令来访问数据库,这里也需要输入你认证admin/admin时候的密码:

查看principal就和之前的命令一样了,这里就不贴图和赘述了。
3. 总结
在Kerberos KDC所在机器并且当前用户是root操作时,直接可以使用kadmin.local进行访问数据库,无需输入密码。
在当前用户是非root用户或在其它机器上操作时,需要先使用kinit命令认证,然后再使用kadmin命令来访问数据库,这里总共需要输入两次密码。
进入Kerberos数据库之后,我们可以对数据库中的principal进行一些操作,这里先不详细说明,后面会出这块的文章。
三、keytab说明
在Ambari页面启用Kerberos向导成功后,会在/etc/security/keytabs目录下生成很多keytab密钥:
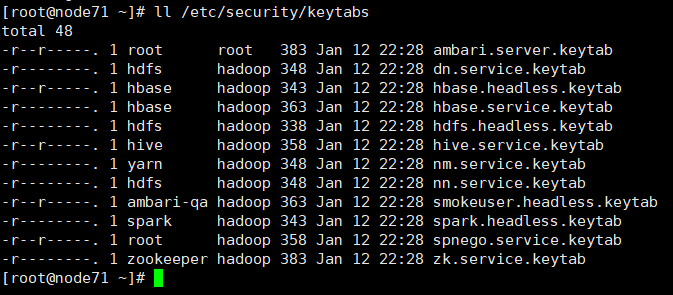
这些keytab密钥与Kerberos数据库中的principal有着一一对应的关系,就像钥匙和锁一样,我们可以使用klist命令来查看keytab内容,比如查看hdfs.headless.keytab内容:
1 | klist -kte /etc/security/keytabs/hdfs.headless.keytab |

由上图可见,hdfs.headless.keytab就是`hdfs-mycluster@EXAMPLE.COM的密钥,也由此可以得出结论,keytab与principal`是一一对应的。
四、YARN配置修改
众所周知,一些大数据服务的执行,需要yarn资源的调度,所以在使用平台服务之前,需要先检查一下yarn的配置,确保执行任务的时候不会因为资源分配问题导致任务被卡住。
假设有集群由三台机器组成,且三台机器的内存为8G,这里需要调整两处地方:
- Yarn容器分配的内存大小
- 资源调度容量的最大百分比,默认为0.2。
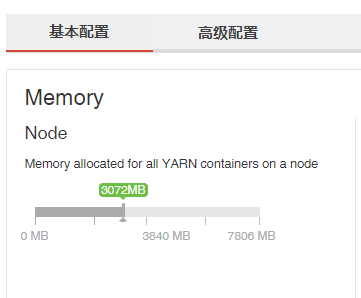
Web UI –> Yarn配置 –> 基本配置 –> Memory allocated for all YARN containers on a node,内存建议调大一些。
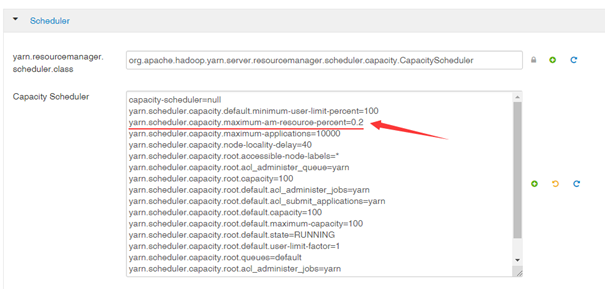
Web UI –> Yarn配置 –> 高级配置 –> Scheduler –> 修改yarn.scheduler.capacity.maximum-am-resource-percent值,百分比建议调高一点,比如0.8(最大值是1)。
如果分配给YARN资源过少,会导致执行集群任务被卡住的问题。
保存修改后的配置,并重启YARN服务。
五、kinit认证
这里采用的是在shell终端上使用命令行进行用户认证的方案。集群内所有的节点均可使用以下命令。
Kinit认证有两种方式,
- 直接认证
Kerberos主体,但需要手动输入密码 - 通过密钥(keytab)认证
Kerberos主体(Principal),不需要手动输入密码,但前提是密钥要与Kerberos主体相匹配。
在理论上来说,使用kinit的任何一种认证方式,只需要认证成功一种就可以任意访问Hadoop所有服务了。
1. 认证自定义用户访问集群服务
1.1 Kerberos认证自定义用户
1.1.1 创建Linux用户
在Linux主机上创建用户,比如lyz,建议在集群的每个节点上都创建lyz用户,否则跑集群任务的时候,有可能会报lyz用户名不存在的错误。
1 | useradd lyz |
1.1.2 创建lyz的Kerberos主体
1 | 进入kadmin.local模式 |
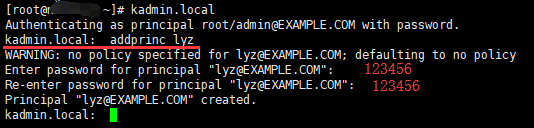
1.1.3 创建keytab文件
使用ktadd命令为`lyz@EXAMPLE.COM创建keytab`文件
1 | ktadd -norandkey -k /etc/security/keytabs/lyz.keytab lyz@EXAMPLE.COM |

1.1.4 Kerberos认证用户
方式一:使用之前设定的密码来认证principal
1 | kinit lyz |

方式二:使用keytab来认证principal
1 | kinit -kt /etc/security/keytabs/lyz.keytab lyz |
查看认证缓存
1 | klist |
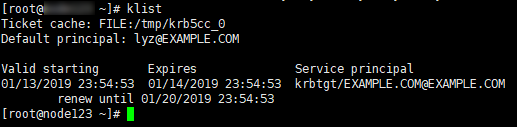
这样的话,在该主机上的root用户下执行操作,就是使用的lyz用户做代理。从理论上来讲,Kerberos认证通过以后,lyz用户可以访问操作集群内的任何服务,但是有的服务拥有ACL权限,比如HBase就有严格的ACL权限控制,具体如何操作下文具体会讲。
以下对各服务的操作,默认都以认证了`lyz@EXAMPLE.COM`为前提。
1.2 使用HDFS
HDFS服务组件本身有着严格的文件权限控制,如果操作不当,很容易出现Permission denied的错误。有两种解决方案(建议第一种),如下所示:
使用hdfs用户创建文件,并修改该文件的所属用户,这样可解决权限问题。(建议使用这种方式)
现在我们使用Kerberos认证的lyz用户来操作HDFS shell。
首先使用hdfs超级用户创建一个文件夹,并改变其文件夹的所有者。
1 | sudo -u hdfs hadoop fs -mkdir /lyz |
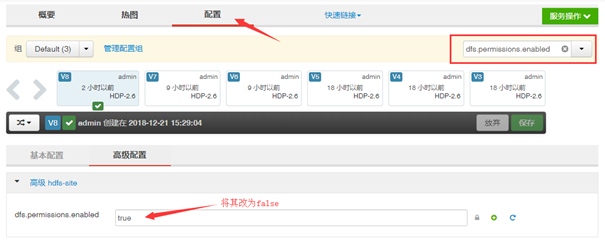
关闭HDFS文件权限设置
Web UI –> HDFS配置 –> 搜索dfs.permissions.enabled,将其值改为false,保存配置,并重启HDFS组件才可生效。如下图所示(但不建议在生产环境中这样做)
上面我们列举了两种解决Permission denied的方案,我们这里使用第一种。
创建目录:
1 | hadoop fs -mkdir /lyz/test |
上传文件:
1 | hadoop fs -put /root/a.log /lyz/test |
浏览文件:
1 | [root@xxx ~]# hadoop fs -ls /lyz/test |
上传的文件a.log的所有者为lyz,这也从侧面验证了Kerberos认证通过之后,是由Kerberos用户代理的Linux上的用户操作。
删除test文件夹:
1 | hadoop fs -rm -r /lyz/test |
1.3 使用Mapreduce
再次说明:执行mapreduce任务的前提是集群内的每个节点上都必须要有lyz这个本地用户,否则任务会执行失败。
编辑mptest.txt文件,内容为:
1 | hello Hadoop |
上传文件至hdfs并执行mapreduce的计数任务:
1 | hadoop fs -put mptest.txt /lyz |
注意:输入路径必须在/lyz目录下,因为lyz用户只拥有操作自己所属文件目录的权限。
任务执行成功:
1 | [root@xxx ~]# hadoop fs -cat /lyz/output1218/part-r-00000 |
1.4 使用hive
由于连接hive时,需要使用的是lyz用户,所以需要确保在HDFS路径上的/user/目录下有lyz文件夹及确保lyz目录及子目录的所有者是lyz,如果目录不存在,则使用以下代码添加:
1 | sudo -u hdfs hadoop fs -mkdir /user/lyz |
Hive有两种连接方式:分别是cli模式和beeline模式。cli模式是通过metaStroe来访问元数据;beeline模式是通过hiveServer2访问元数据。建议使用beeline模式连接hive执行操作。
再次说明:执行hive操作的前提是集群内的每个节点上都必须要有lyz这个本地用户,因为hive有些复杂操作会调用TEZ和Mapreduce来执行任务。
Hive cli操作 – 创建表:
1 | hive |
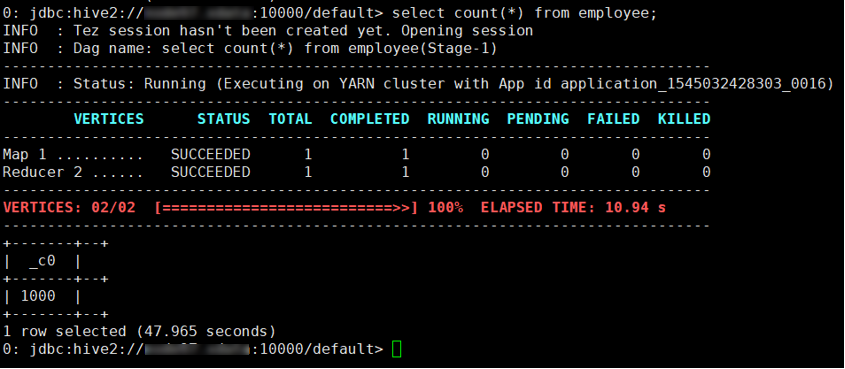
Beeline操作 – 查询表:
(确定hiveserver所在主机,并获取所在主机的hive的principal)
1 | beeline -u 'jdbc:hive2://<hostname>:10000/default;principal=hive/<hostname>@EXAMPLE.COM' |
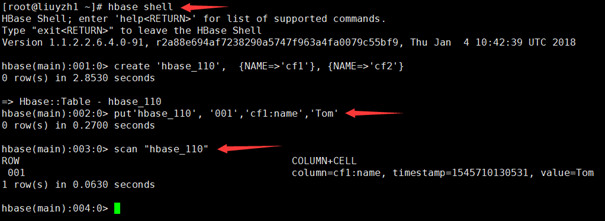
1.5 使用HBase
在1.1里面,我们讲解了如何对自定义用户进行认证,假设我们现在已经有了`lyz@EXAMPLE.COM`的身份,现在我们来访问操作HBase。
1 | hbase shell |
出现错误:

原因分析:
HBase服务启用Kerberos之后,Ambari也会开启HBase自身的权限控制。这时候lyz用户虽然已被认证,但是由于HBase自身还有权限控制,所以还不能执行hbase shell操作,需要使用grant命令对lyz用户进行授权。
解决方案:
切换用户至hbase用户,在其hbase环境下使用hbase.service.keytab进行kerberos认证,
1 | 切换用户 |
这样的话,我们是以HBase超级管理员来访问操作hbase,现在给lyz服赋予相应的权限:
1 | 进入hbase shell |
PS:有时间会写一篇关于HBase服务自身的权限控制的文章。
退出hbase用户:exit

这时候,我们就可以使用lyz用户对HBase进行操作了。
1 | hbase shell |
1.6 使用Spark & Spark2
实验目的
加载hdfs上的一个文件,并实现简单的行数统计及读取第一行。
注意:当在平台中,Spark与Spark2并存时,假如你需要使用Spark2,请更改环境变量,具体操作如下所示:
1 | vim /etc/profile |
也可以临时export,export SPARK_HOME=/usr/hdp/2.6.4.0-91/spark2
输入pyspark进入spark的python模式:
1 | lines = sc.textFile("/lyz/mptest.txt") #读取hdfs上的文件 |
1.7 总结
至此,我们使用了`lyz@EXAMPLE.COM这个principal使用了HDFS、Mapreduce、Hive、HBase、Spark等服务,Kerberos相当于是一个单点登陆系统,经过Kerberos认证之后,使用服务的用户就变成了principal的主名称部分,即lyz。但是具体权限,还需要由具体服务本身的授权机制(**ACL/Sentry等`**)决定。
2. 认证各服务自身用户访问集群服务
在/etc/security/keytabs/目录,存放着我们的keytab密钥,该密钥和Kerberos数据库的Principal是一一匹配的,我们可以查看keytab的内容,来寻找对应的Principal,然后使用kinit -kt认证。
2.1 使用hdfs用户来访问操作HDFS服务
1 | 查看hdfs.headless.keytab对应的principal |
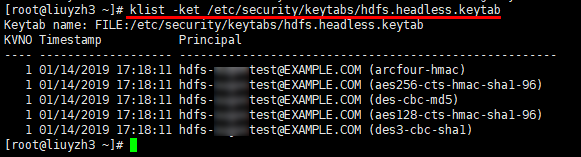
1 | kinit -kt /etc/security/keytabs/hdfs.headless.keytab hdfs-xxxtest@EXAMPLE.COM |

这样的话,就可以以hdfs用户的身份使用HDFS了。
2.2 使用hive用户来访问HIVE服务
1 | 查看hive.service.keytab对应的principal |
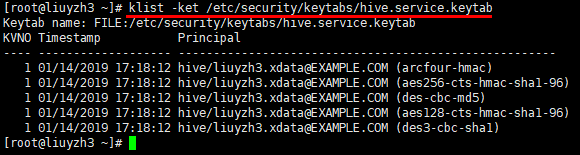
1 | kinit -kt /etc/security/keytabs/hive.service.keytab hive/liuyzh3.xdata@EXAMPLE.COM |

这样的话,就可以以hive用户的身份使用HIVE了。
2.3 使用hbase用户来访问HBASE服务
1 | 查看hbase.service.keytab对应的principal |
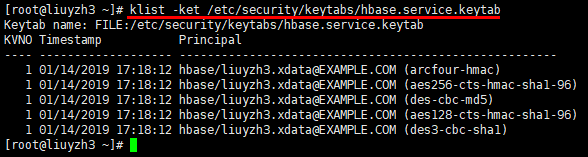
1 | kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/liuyzh3.xdata |
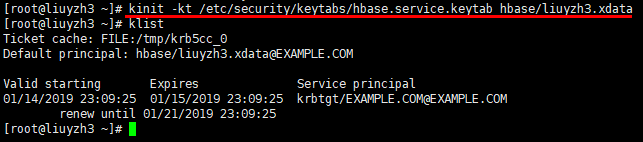
这样的话,就可以以hbase用户的身份使用HBASE了。
2.4 使用spark用户访问SPARK服务
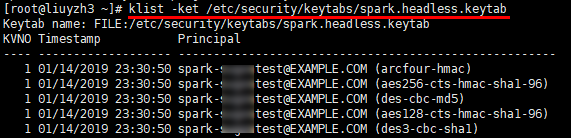
1 | klist -ket /etc/security/keytabs/spark.headless.keytab |
1 | kinit -kt /etc/security/keytabs/spark.headless.keytab spark-xxxtest@EXAMPLE.COM |

这样的话,就可以以spark用户的身份使用SPARK了。
六、总结
本篇文章主要讲解了principal与keytab之间的关系,并详细讲解了Kerberos如何认证用户,并使用HDFS、Mapreduce、HBase、Hive、Spark服务。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2019/01/09/Kerberos/Kerberos应用.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

