sqoop概述及shell操作
一、Sqoop概述
1. 产生背景
基于传统关系型数据库的稳定性,还是有很多企业将数据存储在关系型数据库中;早期由于工具的缺乏,Hadoop与传统数据库之间的数据传输非常困难。基于前两个方面的考虑,需要一个在传统关系型数据库和Hadoop之间进行数据传输的项目,Sqoop应运而生。
2. 简介
Sqoop是一个用于Hadoop和结构化数据存储(如关系型数据库)之间进行高效传输大批量数据的工具。它包括以下两个方面:
- 可以使用Sqoop将数据从关系型数据库管理系统(如MySQL)导入到Hadoop系统(如HDFS、Hive、HBase)中
- 将数据从Hadoop系统中抽取并导出到关系型数据库(如MySQL)
Sqoop的核心设计思想是利用MapReduce加快数据传输速度。也就是说Sqoop的导入和导出功能是通过基于Map Task(只有map)的MapReduce作业实现的。所以它是一种批处理方式进行数据传输,难以实现实时的数据进行导入和导出。
二、Sqoop架构
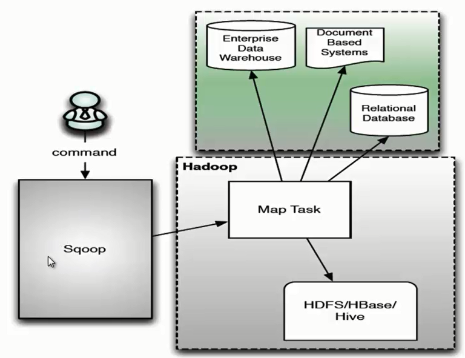
- 用户向Sqoop发起一个命令之后,这个命令会转换为一个基于Map Task的MapReduce作业。
- Map Task 会访问数据库的元数据信息,通过并行的Map Task将数据库的数据读取出来,然后导入Hadoop中。
- 当然也可以将Hadoop中的数据,导入传统的关系型数据库中。
- 它的核心思想就是通过基于Map Task(只有map)的MapReduce作业,实现数据的并发拷贝和传输,这样可以大大提高效率。
三、Sqoop shell操作
| 参数 | 描述 |
|---|---|
| –connect \ |
指定JDBC连接字符串 |
| –username | 指定连接mysql用户名 |
| –password | 指定连接mysql密码 |
1. 将Mysql数据导入到Hadoop中
1.1 数据导入到HDFS
| 参数 | 描述 |
|---|---|
| table \ |
抽取mysql数据库中的表 |
| –target-dir \ |
指定导入hdfs的具体位置。默认生成在为/user/\ |
| -m <数值> | 执行map任务的个数,默认是4个 |
| –direct | 可快速转换数据 |
将mysql数据库中的hive数据库中的roles表数据导入到HDFS中的/user/lyz/111目录下。执行代码如下:
1 | sqoop import \ |
备注:-m参数可以指定map任务的个数,默认是4个。如果指定为1个map任务的话,最终生成的part-m-xxxxx文件个数就为1。在数据充足的情况下,生成的文件个数与指定map任务的个数是等值的。
1.2 数据导入到Hive中
| 参数 | 描述 |
|---|---|
| –hive-import | 将表导入Hive中 |
| –hive-table \ |
指定导入Hive的表名 |
| –fields-terminated-by \ |
指定导入到hive中的文件数据格式 |
| -m <数值> | 执行map任务的个数,默认是4个 |
| –direct | 可快速转换数据 |
将mysql数据库中的hive数据库中的roles表数据导入到Hive数据库中,并生成roles_test表。执行代码如下:
1 | sqoop import \ |
备注:-m参数可以指定map任务的个数,默认是4个。如果指定为1个map任务的话,最终生成在/apps/hive/warehouse/ roles_test目录下的part-m-xxxxx文件个数就为1。在数据充足的情况下,生成的文件个数与指定map任务的个数是等值的。
执行数据导入过程中,会触发MapReduce任务。任务执行成功以后,我们访问Hive验证一下数据是否导入成功。
1 | show tables; |
数据导入成功。
1.3 数据导入到HBase中
| 参数 | 描述 |
|---|---|
| –column-family \ |
设置导入的目标列族 |
| –hbase-row-key \ |
指定要用作行键的输入列;如果没有该参数,默认为mysql表的主键 |
| –hbase-create-table | 如果执行,则创建缺少的HBase表 |
| –hbase-bulkload | 启用批量加载 |
将mysql数据库中的hive数据库中的roles表数据导入到HBase中,并生成roles_test表。执行代码如下:
1 | sqoop import \ |
关于参数–hbase-bulkload的解释:
实现将数据批量的导入Hbase数据库中,BulkLoad特性能够利用MR计算框架将源数据直接生成内部的HFile格式,直接将数据快速的load到HBase中。
细心的你可能会发现,使用–hbase-bulkload参数会触发MapReduce的reduce任务。
执行数据导入过程中,会触发MapReduce任务。任务执行成功以后,我们访问HBase验证一下数据是否导入成功。
1 | hbase(main):002:0> list |
总结:roles_test表的row_key是源表的主键ROLE_ID值,其余列均放入了info这个列族中。
2. 将Hadoop数据导出到Mysql中
Sqoop export工具将一组文件从HDFS导出回Mysql。目标表必须已存在于数据库中。根据用户指定的分隔符读取输入文件并将其解析为一组记录。
默认操作是将这些转换为一组INSERT将记录注入数据库的语句。在“更新模式”中,Sqoop将生成UPDATE替换数据库中现有记录的语句,并且在“调用模式”下,Sqoop将为每条记录进行存储过程调用。
将HDFS、Hive、HBase的数据导出到Mysql表中,都会用到下表的参数:
| 参数 | 描述 |
|---|---|
| –table \ |
指定要导出的mysql目标表 |
| –export-dir \ |
指定要导出的hdfs路径 |
| –input-fields-terminated-by \ |
指定输入字段分隔符 |
| -m <数值> | 执行map任务的个数,默认是4个 |
2.1 HDFS数据导出至Mysql
首先在test数据库中创建roles_hdfs数据表:
1 | USE test; |
将HDFS上的数据导出到mysql的test数据库的roles_hdfs表中,执行代码如下:
1 | sqoop export \ |
执行数据导入过程中,会触发MapReduce任务。任务成功之后,前往mysql数据库查看是否导入成功。
2.2 Hive数据导出至Mysql
首先在test数据库中创建roles_hive数据表:
1 | CREATE TABLE `roles_hive` ( |
由于Hive数据存储在HDFS上,所以从根本上还是将hdfs上的文件导出到mysql的test数据库的roles_hive表中,执行代码如下:
1 | sqoop export \ |
2.3 HBase数据导出至Mysql
目前Sqoop不支持从HBase直接导出到关系型数据库。可以使用Hive周转一下。
2.3.1 创建hive外部表
1 | create external table hive_hbase(id int,CREATE_TIME string,OWNER_NAME string,ROLE_NAME string) |

2.3.2 创建Hive内部表
创建适配于Hive外部表的内部表:
1 | create table if not exists hive_export(id int, CREATE_TIME string, OWNER_NAME string, ROLE_NAME string) |
hive_hbase外部表的源是HBase表数据,当创建适配于hive_hbase外部表的Hive内部表时,指定行的格式为’,’
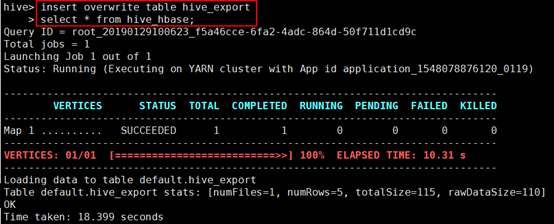
2.3.3 将外部表的数据导入到内部表中
1 | insert overwrite table hive_export |
2.3.4 创建Mysql表
1 | CREATE TABLE `roles_hbase` ( |
2.3.5 执行sqoop export
1 | sqoop export \ |
查看mysql中的roles_hbase表,数据成功被导入。
备注:在创建表的时候,一定要注意表字段的类型,如果指定表类型不一致,有可能会报错。
3. 总结
使用sqoop import/export命令,可以实现将关系型数据库中的数据与Hadoop中的数据进行相互转化,其中一些转化的细节,可以指定参数实现。在执行过程中,sqoop shell操作,会转化为MapReduce任务来实现数据的抽取。
更多的sqoop操作,详情请参见:http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2019/02/15/Sqoop/sqoop概述及shell操作.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

