如何在HUE上通过oozie调用Spark工作流
HUE版本:3.12.0
Spark版本:1.6.3
Ambari版本:2.6.1.0
HDP版本:2.6.4
前言
通过浏览器访问
ip:8888登陆HUE界面,首次登陆会提示你创建用户,这里使用账号/密码:hue/hue登陆。
一、背景
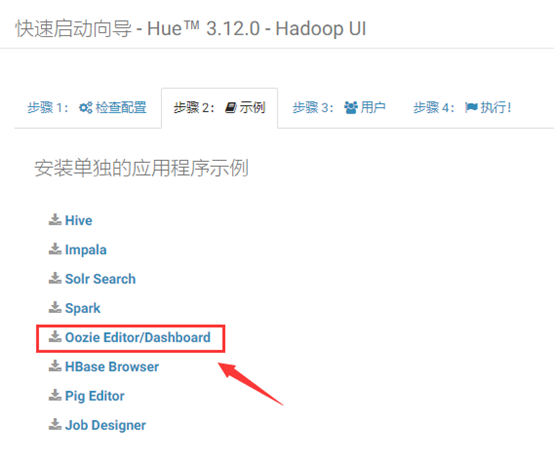
访问ip:8888/about/#step2,点击下载Oozie Editor/Dashboard,可以下载应用程序示例。如下图所示:
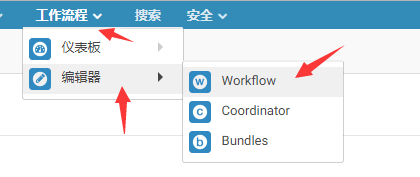
下载完成之后,访问workflow编辑器,会看到spark的程序示例。在这对该示例如何执行进行讲解。如下两图所示:

二、业务场景
通过启动Spark Java程序复制文件到HDFS文件系统中。
三、上传jar包
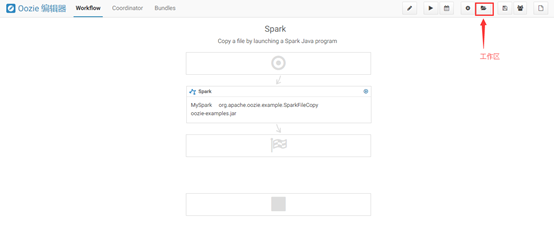
点击spark示例程序,点击“工作区”,如下图所示:
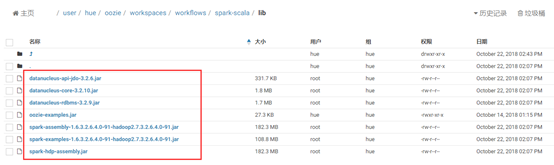
将本地/usr/hdp/2.6.4.0-91/spark/lib目录下的jar包上传到上述工作区的lib文件夹内,执行命令:
1 | sudo -u hdfs hadoop fs -put /usr/hdp/2.6.4.0-91/spark/lib/* /user/hue/oozie/workspaces/workflows/spark-scala/lib/ |
执行结果如图所示:
四、检查Workflow配置
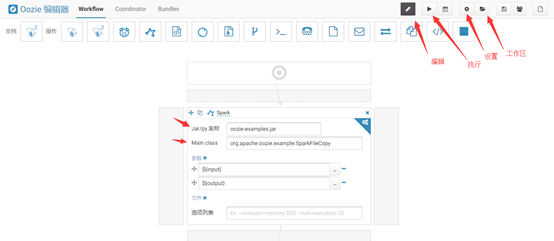
点击“编辑”,出现如下图所示,其中jar/py名称是oozie-examples.jar,main class(主类)是org.apache.oozie.example.SparkFileCopy,参数为:${input},${output}。在这里,我们保持默认配置。如下图所示:
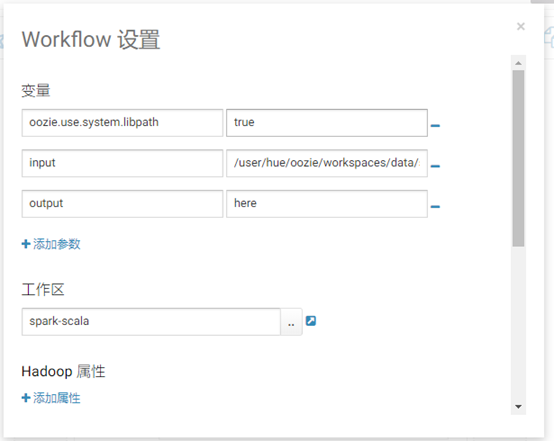
点击“设置”,可以更改Workflow设置,其中变量input的值就是我们要复制的文件路径。在这里,我们保持默认配置,如下图所示:
五、执行Workflow
点击“执行”按钮,选择output输出路径,这里我选择输出到该示例的工作区: /user/hue/oozie/workspaces/workflows/spark-scala/output,点击“提交”。
备注:输出路径会自动生成,不能选择已有文件。
六、查看结果
打开/user/hue/oozie/workspaces/workflows/spark-scala/output,会生成三个文件,如下图所示:

七、总结
在HUE上通过oozie调用Spark工作流:
- 本篇文章是使用的HUE官方自带的Spark示例,我们需要提前下载。
- 上传Spark相关jar包到该Spark Workflow的工作区
- 检查Workflow配置
- 选择输入输出参数,执行Workflow
推荐链接
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2019/02/21/HUE/如何在HUE上通过oozie调用Spark工作流.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

