HBase基础(一):架构理解
版本说明:
通过 HDP 3.0.1 安装的 HBase 2.0.0
一、概述
Apache HBase 是基于 Hadoop 构建的一个分布式的、可伸缩的海量数据存储系统。常被用来存放一些海量的(通常在TB级别以上)、结构比较简单的数据,如历史订单记录,日志数据,监控 Metris 数据等等, HBase 提供了简单的基于 Key 值的快速查询能力。
HBase 实际上更像是“数据存储”而不是“数据库”,因为它缺少 RDBMS 中找到的许多功能,例如二级索引,触发器和高级查询语言等。
但是 HBase 具备许多 RDBMS 没有的功能:
- 通过 RegionServer 扩展存储。如果 HBase 集群从10个 RegionServer 扩展到20个 RegionServer ,那么在存储和处理能力方面都会翻倍。
- 强大的读写能力。
- 自动分片。 HBase 表通过 Region 分布在 HBase 上,并且随着数据的增长, Region 会自动分割和重新分配。
- RegionServer 自动故障转移。如果一个 RegionServer 宕机或进程故障,由 Master 负责将它原来所负责的 Regions 转移到其它正常的 RegionServer 上继续提供服务。
- Hadoop/HDFS 集成: HBase 使用 HDFS 作为其分布式文件系统。
- MapReduce 集成: HBase 支持通过 MapReduce 进行大规模并行处理,将 HBase 用作源和接收器。
- 支持多语言接口:除了支持 Java API ,还可通过内嵌的 Thrift 服务实现其它语言接口的调用,比如 C++ 、 Python 。
- Block Cache and Bloom Filters : HBase 支持块缓存和 Bloom 过滤器,以实现高容量查询优化。
方便运维管理: HBase 提供 Web UI ,用于操作查看以及监控 JMX 指标。
HBase 并不适合所有场景。 首先,确保您有足够的数据。如果你有数亿或数十亿行,那么 HBase 是一个很好的候选者。如果你只有几千/百万行,那么使用传统的 RDBMS 可能是一个更好的选择。
二、整体架构
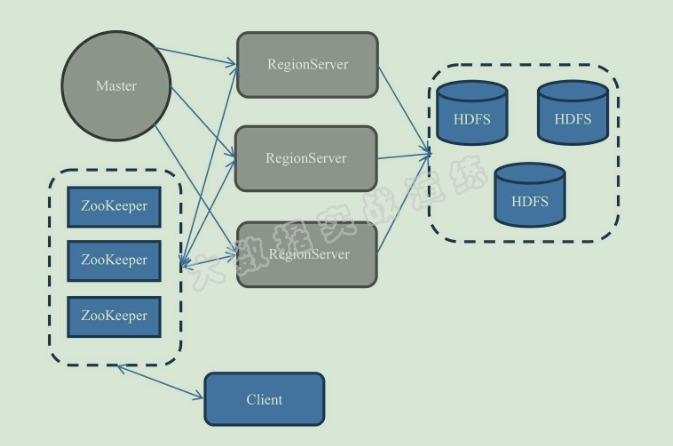
先简单说一下 HBase 的整体架构, 一般一个 HBase 集群由一个 Master 服务和几个 RegionServer 服务组成。 Master 服务负责维护表结构信息;实际的数据都存储在 RegionServer 上,最终 RegionServer 保存的表数据会直接存储在 HDFS 上。
1. HBase Master
HBase 的管理节点,通常在一个集群中设置一个 主Master ,一个 备Master ,主备角色的”仲裁”由 ZooKeeper 实现。 HBase Master 的主要职责有(参考的HBase官网):
- 负责管理监控所有的 RegionServer ,负责 RegionServer 故障转移。如果一个 RegionServer 宕机或进程故障,由 Master 负责将它原来所负责的 Regions 转移到其它正常的 RegionServer 上继续提供服务。
- 负责表的相关操作( create、modify、remove、enable、disable ),列族的相关操作( add、modify、remove ),还有 Region 的 move、assign、unassign 。
平衡集群负载并定期检查并清理 hbase:meta 表。
HBase 有一点很特殊:客户端获取数据由客户端直连 RegionServer 的,所以你会发现 Master 挂掉之后你依然可以查询数据,但不能新建表了。这也从侧面说明 HBase 不像 HDFS 强依赖于 NameNode 那样依赖 Master , Master 与 RegionServer 各有各的分工。
2. RegionServer
负责服务和管理 Region 。在分布式集群中,建议 RegionServer 与 DataNode 按 1:1 比例安装,这种部署的优势在于: RegionServer 中的数据文件可以存储一个副本于本机的 DataNode 节点中,从而在读取时可以利用 HDFS 中的”短路径读取(Short Circuit)”来绕过网络请求,降低读取时延。
RegionServer 的主要职责有(参考的HBase官网):
数据的读取和写入,比如: get , put , delete , next 等。
Region 的拆分和压缩。
在这里对 Region 的拆分做一些补充说明:虽然拆分 Region 是 RegionServer 做出的本地决策,但拆分过程本身必须与许多参与者协调。 RegionServer 在 Region 拆分之前和之后通知 Master ,更新 .META. 表,以便客户端可以发现新的 子Region ,并重新排列 HDFS 中的目录结构和数据文件。
一些后台操作:
- 检查拆分并处理轻微压缩。
- 检查主要的压缩。
- 定期刷新 MemStore 到 StoreFiles 中的内存中写入。
- 定期检查 RegionServer 的 WAL 。
3. Zookeeper
ZooKeeper 存储着 hbase:meta 信息。 hbase:meta 表记录着 HBase 中所有 Region 的相关信息。
所以 RegionServer 非常依赖 Zookeeper 服务,可以说没有 Zookeeper 就没有 HBase 。 Zookeeper 在 HBase 中扮演的角色类似一个管家。 ZooKeeper 管理了 HBase 所有 RegionServer 的信息,包括具体的数据段存放在哪个 RegionServer 上。
客户端会与 RegionServer 通信。每次与 HBase 连接,其实都是先与 ZooKeeper 通信,查询出哪个 RegionServer 需要连接,然后再连接 RegionServer 。
4. HDFS
由于 HBase 在 HDFS 上运行(并且每个 StoreFile (也就是 HFile ) 都作为 HDFS 上的文件写入),因此了解HDFS架构非常重要,尤其是在存储文件,处理故障转移和复制块方面。
NameNode
NameNode 负责维护文件系统元数据。
DataNode
DataNode 负责存储 HDFS 块,也就是真实数据。
最终的 HBase 相关架构图如下图所示:
三、RegionServer内部探险
HBase RegionServer :负责数据的读取和写入。一个 RegionServer 里面包含一个 WAL 与 一个或多个 Region 。当数据量小的时候,一个 Region 足以存储所有数据;但当数据量大的时候, RegionServer 会拆分 Region ,通知 Hbase Master 将多个 region 分配到一个或多个 RegionServer 中。
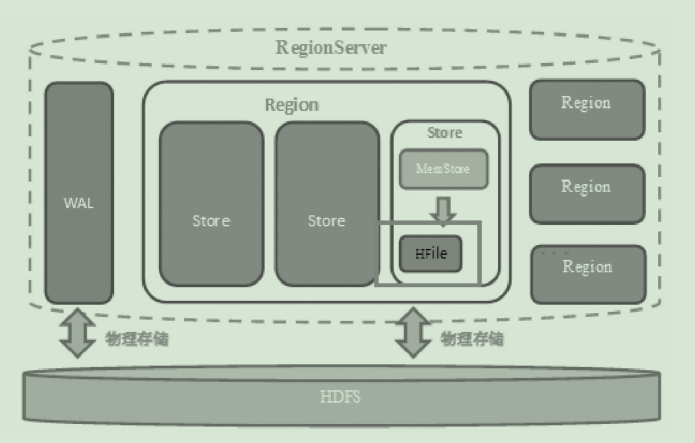
从这张图上我们可以看出一个 RegionServer 包含有:
1. 一个WAL
预写日志, WAL 是 Write-Ahead Log 的缩写。从名字就可以看出它的用途,就是:预先写入。是 RegionServer 在处理数据插入和删除的过程中用来记录操作内容的一种日志。
当操作到达 Region 的时候, RegionServer 先不管三七二十一把操作写到 WAL 里面去,再把数据放到基于内存实现的 Memstore 里,等数据达到一定的数量时才刷写( flush )到最终存储的 HFile 内。在一个 regionServer 上的所有的 Region 都共享一个 WAL 。
而如果在这个过程中服务器宕机或者断电,那么数据就丢失了。 WAL 是一个保险机制,数据在写到 MemStore 之前,先被写到 WAL 了。这样当故障恢复的时候可以从 WAL 中恢复数据。
2. 多个Region
Region 相当于一个数据分片。它采用了”Range分区”,将 Key 的完整区间切割成一个个的”Key Range” ,每一个”Key Range”称之为一个 Region 。每一个 Region 都有 起始 rowkey 和 结束 rowkey ,代表了它所存储的 row 范围。
也可以这么理解:将 HBase 中拥有数亿行的一个大表,横向切割成一个个”子表”,这一个个”子表”就是 Region 。 Region 是 HBase 中负载均衡的基本单元,当一个 Region 增长到一定大小以后,会自动分裂成两个( Region 有分裂策略,本篇文章不涉及)。
我创建了一个表,内含5个 Region , Master 将 Region 分配到了两个 RegionServer 中,如下图所示:
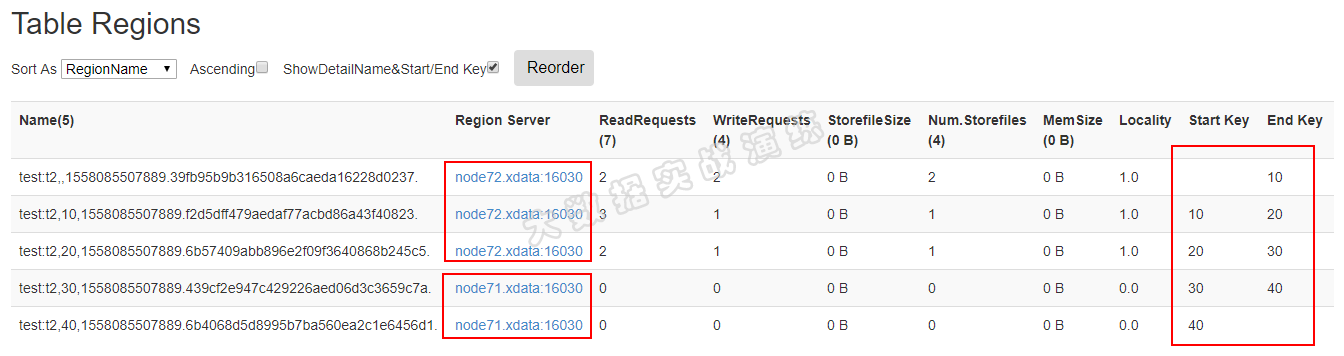
这也从侧面表明:一个表中的数据,会被分配到一个或多个 Region 中存储,而 Region 受 HBase Master 管控,被分配到一个或多个 RegionServer 中。
接下来我们来看单个 Region 内部结构,如下图所示:
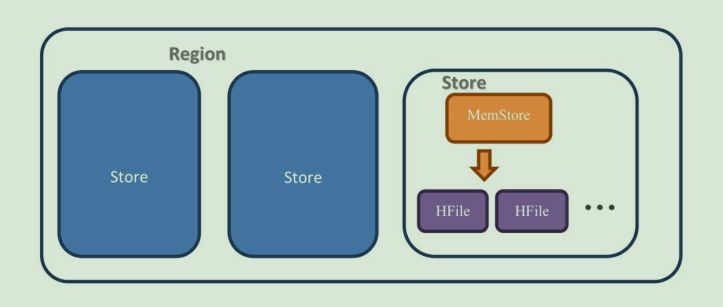
每一个 Region 内都包含有多个 Store 实例。一个 Store 对应一个 列族 的数据,如果一个表有两个列族,那么在一个 Region 里面就有两个 Store 。
在最右边的单个 Store 的解剖图上,我们可以看到 Store 内部有 MemStore 和 HFile 这两个组成部分。
2.1 MemStore
MemStore :数据被写入 WAL 之后就会被加载到 MemStore 中去。每个 Store 里面都只有一个 MemStore ,用于在内存中保存数据。 MemStore 的大小增加到超过一定阈值的时候就会被刷写到 HDFS 上,以 HFile 的形式被持久化起来。
2.2 HFile
HFile(StoreFile) : HFile 是数据存储的实际载体,我们创建的所有表、列等数据最终都存储在 HFile 里面。我在 HFile 后面的括弧里面写了 StoreFile ,意思是你在很多资料中经常会看到管 HFile 叫 StoreFile 。其实叫 HFile 或者 StoreFile 都没错, HBase 是基于 Java 编写的,那么所有物理上的东西都有一个对象跟它对应,在物理存储上我们管 MemStore 刷写而成的文件叫 HFile , StoreFile 就是 HFile 的抽象类而已。
假如有一个数据量巨大的表,那么 Region 相当于将这表横向切割,列族又将表纵向切割。如下图所示,每个 Region 都有两个列族,也就对应着两个 Store 。
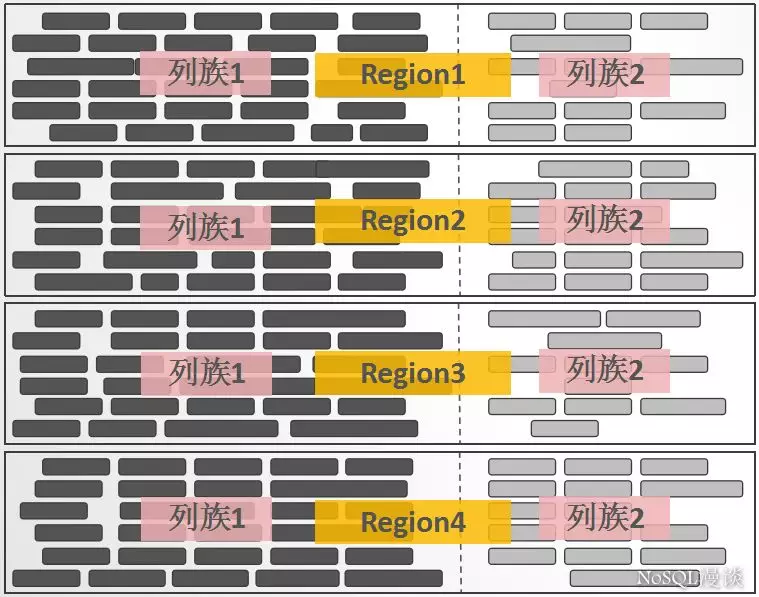
四、总结
本篇文章介绍了 HBase 的优缺点、使用场景,使用大多数文字对 HBase 的架构进行说明:
- HBase 服务依赖于 HDFS 与 Zookeeper 。
- HBase 集群又分为:
- 一个 HBase Master (服务高可用时,可启动多个 HBase Master , Active-Standby 模式)
- 多个 HBase RegionServer :
- 一个 WAL
- 多个 Region :
- 多个 Store :
- 一个 MemStore
- 多个 HFile 文件
- 多个 Store :
注:本文主要参考 HBase 官网、《HBase不睡觉书》以及【NoSQL漫谈】公众号:
谢谢!
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2019/05/16/HBase/HBase基础(一):架构理解.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

