快速掌握 MongoDB:索引详解及实操,explain()
在项目开发中需要对 MongoDB 查询进行优化,在网上查阅资料的时候发现了一篇好文章,对 MongoDB 索引介绍的挺清楚的,非常适合 MongoDB 新手阅读。
参考链接:https://www.cnblogs.com/wyy1234/p/11032163.html
作者:捞月亮的猴子
一、MongoDB 索引的管理
本节介绍 MongoDB 中的索引,熟悉 mysql/sqlserver 等关系型数据库的小伙伴应该都知道索引对优化数据查询的重要性。我们先简单了解一下索引:索引的本质就是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据(数据 row 或者 document 的物理地址,索引可以大大加快查询的速度,这是因为使用索引后可以不再扫描全表来定位某行的数据,而是先通过索引表找到该行数据对应的物理地址(多数为 B-tree 查找),然后通过地址来访问相应的数据。
索引可以加快数据检索、排序、分组的速度,减少磁盘 I/O ,但是索引也不是越多越好,因为索引本身也是数据表,需要占用存储空间,同时索引需要数据库进行维护,当我们对索引列的值进行增改删操作时,数据库需要更新索引表,这会增加数据库的压力。
我们要根据实际情况来判断哪些列适合添加索引,哪些列不适合添加索引,一般遵循的规律如下:
- 主/外键列,主键用于强制该列的唯一性和组织表中数据的排列结构;外键可以加快连接的速度;
- 经常用于比较的类(大于小于等于等),因为索引已经排序,值就是大于/小于的分界点;
- 经常进行范围搜索,因为索引已经排序,其指定的范围是连续的;
- 经常进行排序的列,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 经常进行分组的列,因为索引已经排序,同一个值的所有数据地址会聚集在一块,很方便分组。
我们看一下 MongoDB 的索引使用,首先往 userinfos 集合中插入一些数据:
1 | db.userinfos.insertMany([ |
索引的增删改查还是十分简单的,我们看一下索引管理的几个方法:
1 | // 创建索引,值 1 表示正序排序,-1 表示倒序排序;background 为 true 表示索引在后台创建,默认为false。 |
二、MongoDB 中常用的索引类型
1、单键索引
单键索引( Single Field Indexes )顾名思义就是单个字段作为索引列,MongoDB 的所有 collection 默认都有一个单键索引 _id ,我们也可以对一些经常作为过滤条件的字段设置索引,如给 age 字段添加一个索引,语法十分简单:
1 | // 给age字段添加升序索引 |
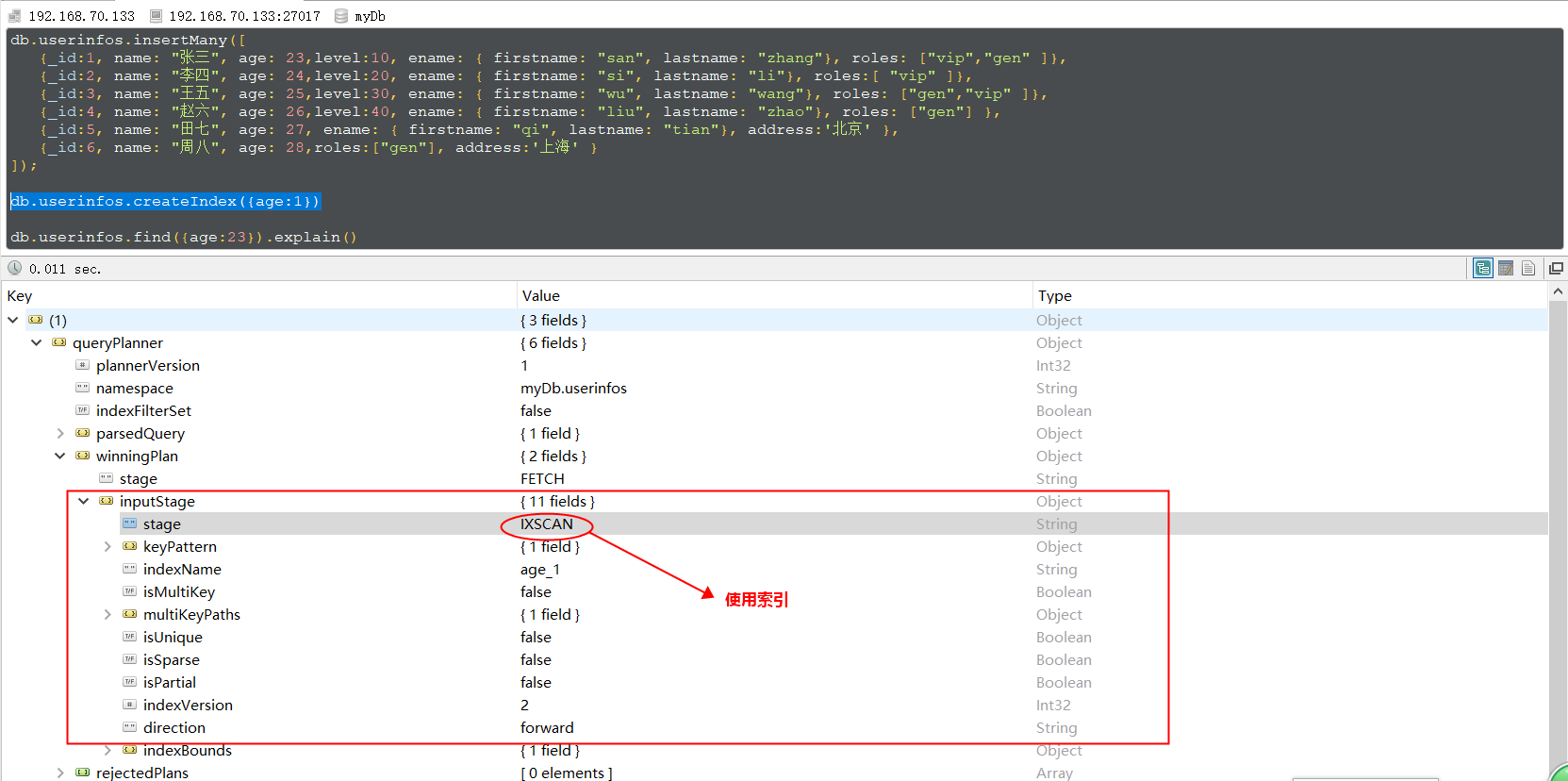
其中 {age:1} 中的 1 表示升序,如果想设置倒序索引的话使用 db.userinfos.createIndex({age:-1}) 即可。我们通过 explain() 方法查看查询计划,如下图,看到查询 age=23 的 document 时使用了索引,如果没有使用索引的话stage 为 COLLSCAN 。
因为 document 的存储是 bson 格式的,我们也可以给内置对象的字段添加索引,或者将整个内置对象作为一个索引,语法如下:
1 | // 1.内嵌对象的某一字段作为索引 |
2、复合索引
复合索引( Compound Indexes )指一个索引包含多个字段,用法和单键索引基本一致。使用复合索引时要注意字段的顺序,如下添加一个 name 和 age 的复合索引,name 正序,age 倒序,document 首先按照 name 正序排序,然后 name 相同的 document 按 age 进行倒序排序。MongoDB 中一个复合索引最多可以包含 32 个字段。
1 | // 添加复合索引,name正序,age倒序 |
执行查询时查询计划如下:

3、多键索引
多键索引 ( mutiKey Indexes ) 是建在数组上的索引,在 MongoDB 的 document 中,有些字段的值为数组,多键索引就是为了提高查询这些数组的效率。看一个栗子:准备测试数据,classes 集合中添加两个班级,每个班级都有一个 students 数组,如下:
1 | db.classes.insertMany([ |
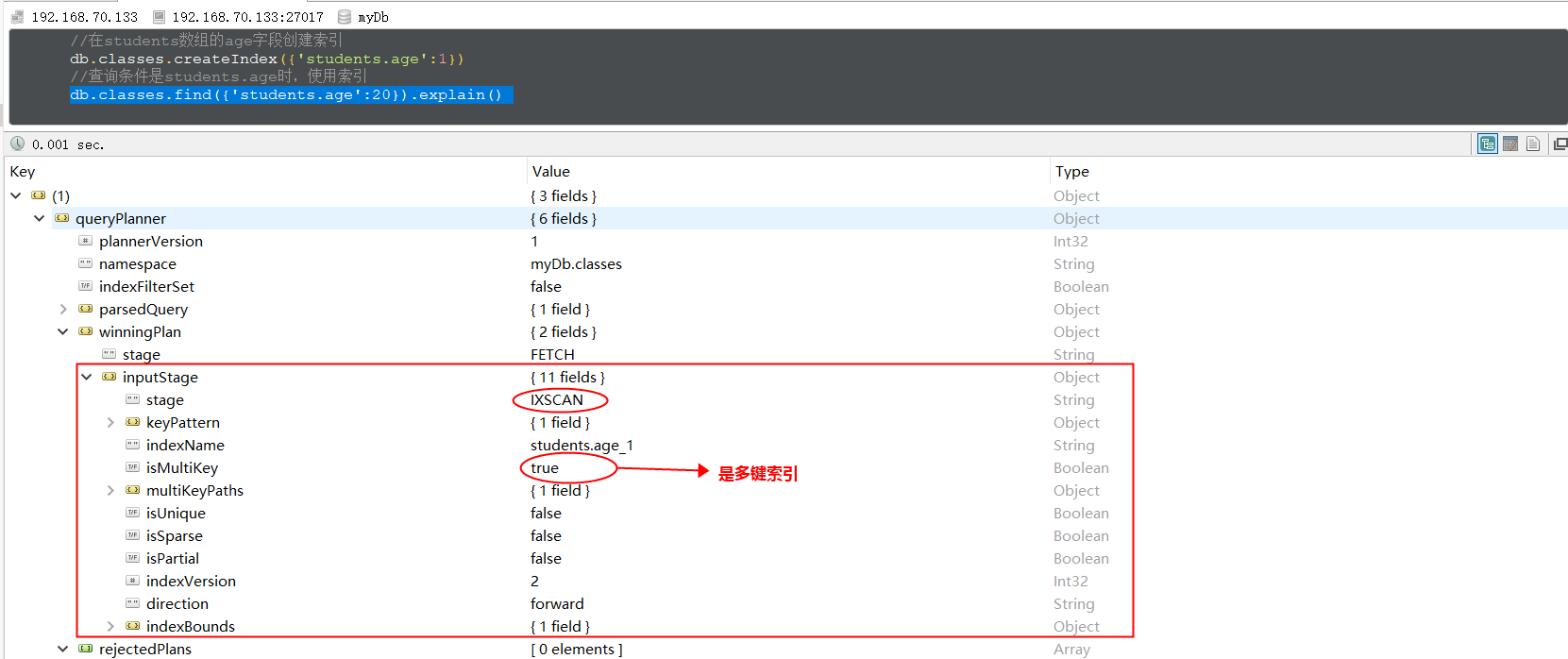
为了提高查询 students 的效率,我们使用 db.classes.createIndex({‘students.age’:1}) 给 students 的 age 字段添加索引,age 是数组中的字段哦,然后使用索引,如下图:
4、哈希索引
哈希索引( hashed Indexes )就是将 field 的值进行 hash 计算后作为索引,其强大之处在于实现 O(1) 查找,当然用哈希索引最主要的功能也就是实现定值查找,对于经常需要排序或查询范围查询的集合不要使用哈希索引。

三、MongoDB中常用的索引属性
1、唯一索引
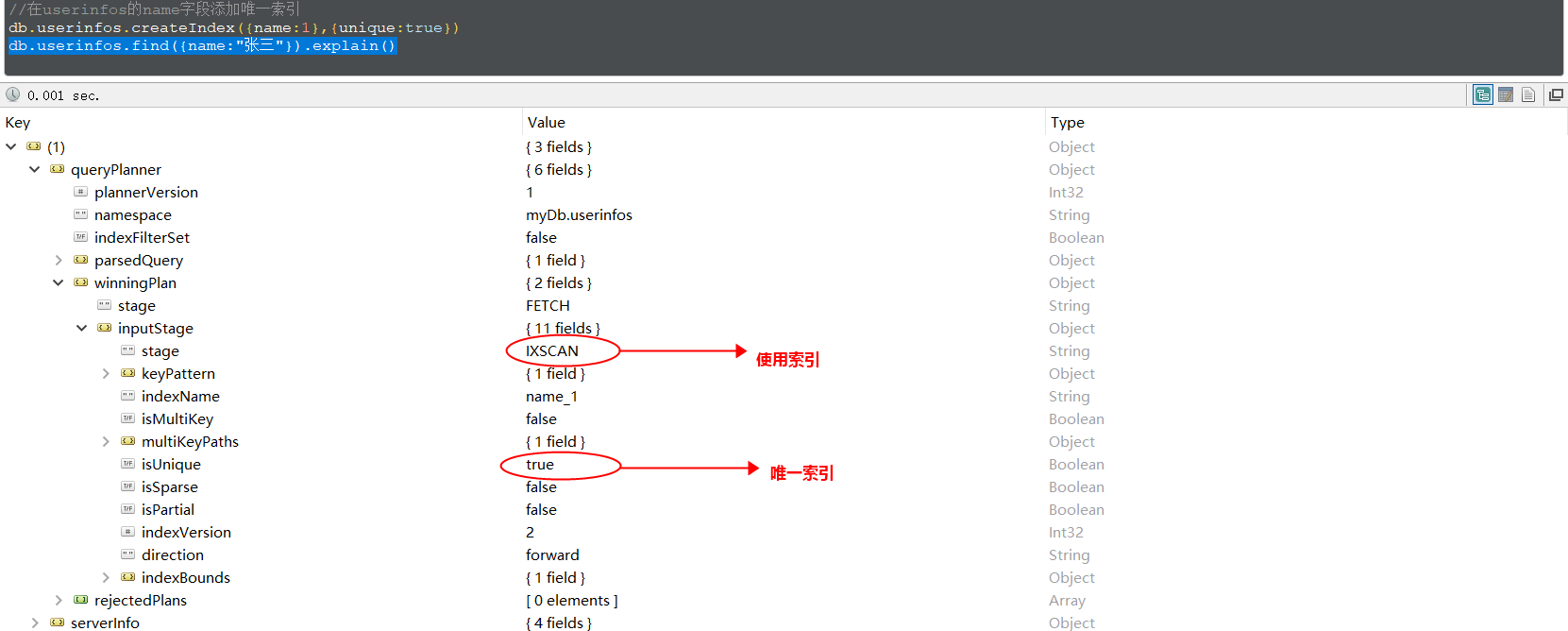
唯一索引 (unique indexes) 用于为 collection 添加唯一约束,即强制要求 collection 中的索引字段没有重复值。添加唯一索引的语法:
1 | // 在userinfos的name字段添加唯一索引 |
看一个使用唯一索引的栗子:
2、局部索引
局部索引 (Partial Indexes) 顾名思义,只对 collection 的一部分添加索引。创建索引的时候,根据过滤条件判断是否对 document 添加索引,对于没有添加索引的文档查找时采用的全表扫描,对添加了索引的文档查找时使用索引。使用方法也比较简单:
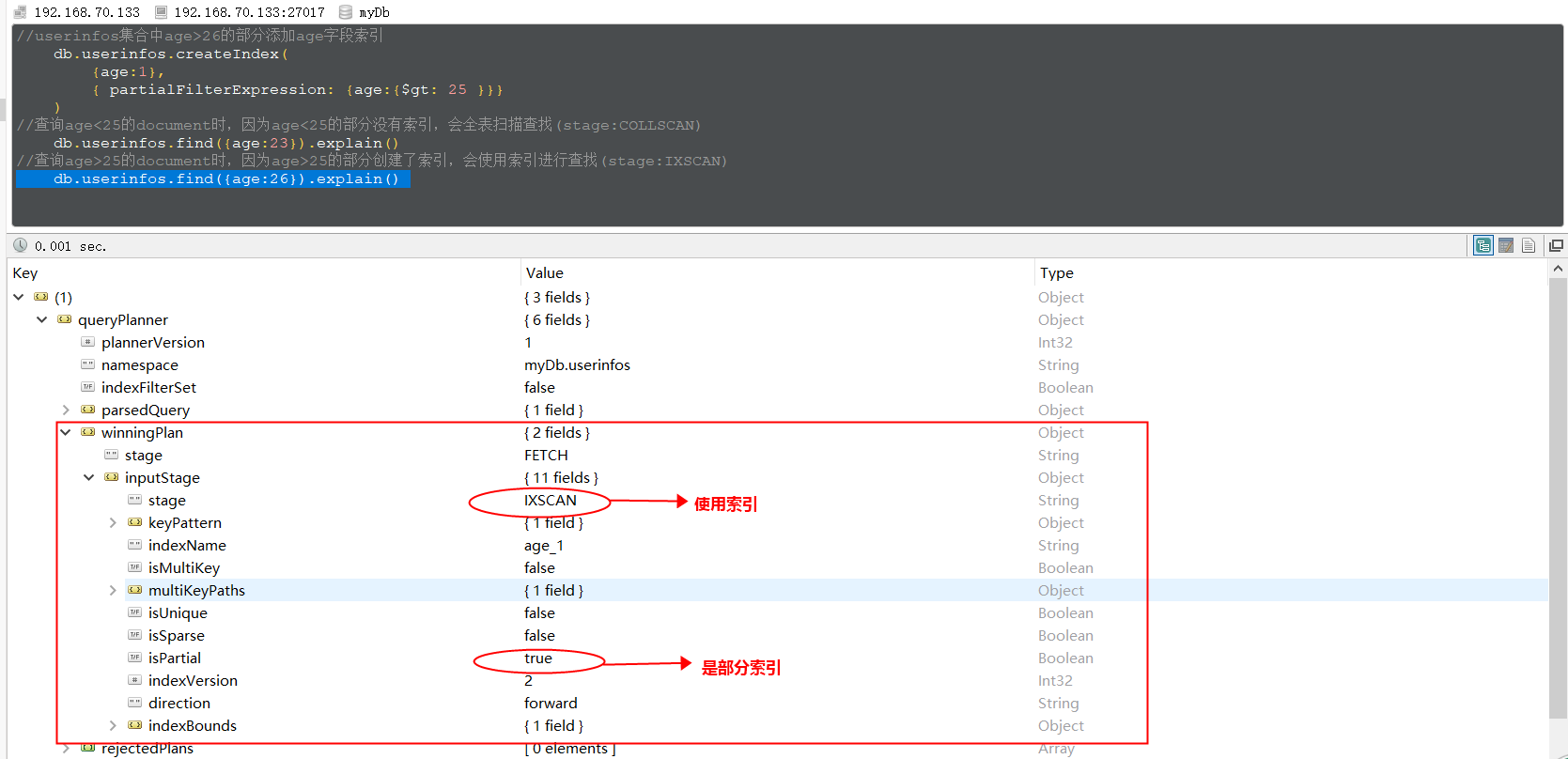
1 | //userinfos集合中age>25的部分添加age字段索引 |
当查询 age=23 的记录时,stage 为 COLLSCAN,当查询 age=26 的记录时,使用了索引,如下:
3、稀疏索引
稀疏索引 (sparse indexes) 在有索引字段的 document 上添加索引,如在 address 字段上添加稀疏索引时,只有 document 有 address 字段时才会添加索引。而普通索引则是为所有的 document 添加索引,使用普通索引时如果 document 没有索引字段的话,设置索引字段的值为 null 。
稀疏索引的创建方式如下,当document包含address字段时才会创建索引:
1 | //创建在address上创建稀疏索引 |
看一个使用稀疏索引的栗子:

4、TTL索引
TTL索引 (TTL indexes) 是一种特殊的单键索引,用于设置 document 的过期时间,MongoDB 会在 document 过期后将其删除,TTL 非常容易实现类似缓存过期策略的功能。我们看一个使用 TTL 索引的栗子:
1 | // 添加测试数据 |
注意:TTL索引只能设置在 date 类型字段(或者包含 date 类型的数组)上,过期时间为字段值 +exprireAfterSeconds ;document 过期时不一定就会被立即删除,因为 MongoDB 执行删除任务的时间间隔是60s;capped Collection(固定集合) 不能设置 TTL 索引,因为 MongoDB 不能主动删除 capped Collection 中的 document 。
四、总结
本文介绍了 MongoDB 中常用的索引和索引属性,索引对提升数据检索的速度十分重要,在数据量比较大的时候一般都要在 collection 上建立索引。在建立索引的测试中,可以使用 explain() 方法来查看 MongoDB 在语句查询中走没走索引,一般就是看 queryPlanner.winningPlan.inputStage.stage 属性,IXSCAN 表示走索引扫描,COLLSCAN 表示 走集合扫描。
MongoDB 提供的索引种类很丰富,总会有几种适用于我们的业务,除了上边介绍的索引外,MongoDB 还支持 text index 和 一些地理位置 相关的索引,这里不再介绍,有兴趣的小伙伴可以到官网研究下。
官网地址:https://docs.mongodb.com/manual/indexes/
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。 各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2020/03/14/MongoDB/mongodb-index-introduce.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

